MIT 6.5840 is a well-known distributed systems course taught at MIT. It covers important topics such as fault tolerance, consistency, replication, and sharding. The course goes beyond theory into designing and building real distributed systems, with representative examples including MapReduce, Raft, and ZooKeeper.
In this series of posts, I document what I learned from the lectures and labs. I hope it serves as a reference for myself and for anyone interested in distributed systems.
In this post, we explore MIT 6.5840 Lab 1, where you build a simple MapReduce framework.
1. What is MapReduce?
MapReduce is a widely used programming model for processing large datasets by splitting work and running it in parallel. It is an effective way to speed up computation at scale. The original paper by Jeff Dean and Sanjay Ghemawat — MapReduce: Simplified Data Processing on Large Clusters — is well worth reading; here I summarize the main ideas and share how I implemented them.
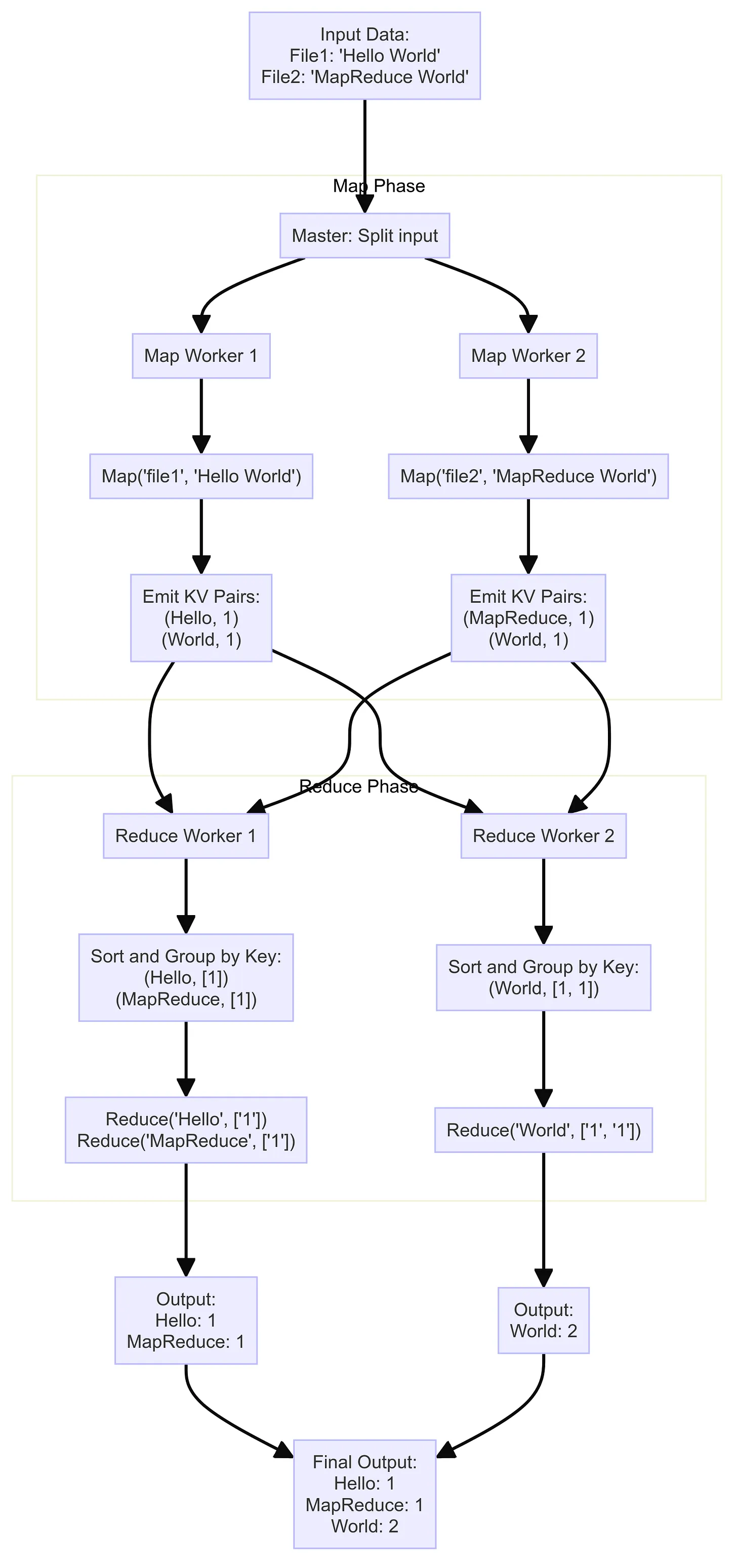
We will use a simple example from the paper: counting word occurrences. Suppose you have a large collection of text files and you want to count how many times each word appears. With MapReduce, you only define two functions, map and reduce, and the framework handles the rest.
1.1. The Map function
// KeyValue represents one key-value pair.
type KeyValue struct {
Key string
Value string
}
// Map is called once per input file.
func Map(filename string, contents string) []KeyValue {
// Predicate: treat non-letters as word separators.
ff := func(r rune) bool { return !unicode.IsLetter(r) }
// Split text into words; ff strips punctuation, digits, etc.
words := strings.FieldsFunc(contents, ff)
kva := []KeyValue{}
for _, w := range words {
// For each word, emit (word, "1").
kv := KeyValue{w, "1"}
kva = append(kva, kv)
}
return kva
}
Explanation:
The framework calls Map once per input file.
filenameis the file name (unused in this example).contentsis the entire file as a string.- The goal is to tokenize the text and emit
(word, "1")for each word.
Example: if the file contains:
Go is expressive, concise, clean, and efficient.
the return value is:
[]KeyValue{
{"Go", "1"},
{"is", "1"},
{"expressive", "1"},
{"concise", "1"},
{"clean", "1"},
{"and", "1"},
{"efficient", "1"},
}
These intermediate key-value pairs are then sent to reduce workers to sum counts per word.
1.2. The Reduce function
// Reduce is called once per distinct key (word).
func Reduce(key string, values []string) string {
// Return the total count for this word as a string.
return strconv.Itoa(len(values))
}
Explanation:
Reduce runs once per distinct key produced by the map tasks.
keyis the word being aggregated.valueslists every"1"emitted byMapfor that word.
Because each map emits ("word", "1"), len(values) is the total occurrence count.
Example: if "Go" appears five times across all files:
Reduce("Go", []string{"1", "1", "1", "1", "1"})
returns "5".
1.3. How the MapReduce framework uses these functions
You supply map and reduce; the framework orchestrates everything else. There are two main components:
- Coordinator: manages the whole job.
- Workers: execute map and reduce tasks.
The pipeline works as follows:
- Map phase
- The coordinator splits input into M pieces.
- Each piece is assigned to a worker, which runs
map. mapoutputs intermediate key-value pairs, partitioned into R buckets (one per reduce task) and written to disk.
- Reduce phase
- After all map tasks finish, the coordinator schedules reduce tasks.
- Each reduce worker:
- Reads its share of intermediate data from disk.
- Sorts by key to group values for the same key.
- Calls
reducewith the key and its values. - Writes final output to disk.
- Completion
- When every map and reduce task is done, workers stop and the job is finished.
The diagram below illustrates how the pieces fit together from map through reduce.
2. Implementation
(Note: this is not the most optimized code; there is room to improve. For this first version I prioritized clarity.)
The code lives mainly in coordinator.go and worker.go. For learning purposes, we assume the coordinator and workers run on the same machine.
2.1. Coordinator
We start with two core structs: Task and Coordinator.
// TaskStatus is the lifecycle state of a task.
type TaskStatus int
const (
NotStarted TaskStatus = iota // Not yet assigned
Assigned // Assigned to a worker
Completed // Finished successfully
)
// Task tracks status and when it was assigned.
type Task struct {
taskStatus TaskStatus
assignedAt time.Time
}
// Coordinator orchestrates map and reduce tasks.
type Coordinator struct {
mu sync.Mutex
Files []string
MapTasks []Task
ReduceTasks []Task
done chan struct{}
}
Explanation:
- Each
Taskis one unit of work. It storesNotStarted,Assigned, orCompleted, plusassignedAtso the coordinator can detect slow or dead workers and reassign work. Coordinatorholds:mu: mutex for shared state.Files: input file names.MapTasks/ReduceTasks: slices of tasks.done: signals shutdown when the job completes.
2.1.1. Starting the RPC server
Workers talk to the Coordinator over RPC. Here is server(), which starts the RPC server:
// server starts an RPC server for workers to connect to.
func (c *Coordinator) server() {
rpc.Register(c)
rpc.HandleHTTP()
sockname := coordinatorSock()
os.Remove(sockname)
l, e := net.Listen("unix", sockname)
if e != nil {
log.Fatal("listen error:", e)
}
go http.Serve(l, nil)
}
This creates a Unix domain socket and runs an HTTP server that dispatches RPCs from workers.
2.1.2. Initializing the coordinator
MakeCoordinator constructs a Coordinator, allocates map/reduce tasks from the input file count and desired nReduce, then starts periodic checks and the RPC server:
// MakeCoordinator creates a new Coordinator.
func MakeCoordinator(files []string, nReduce int) *Coordinator {
c := Coordinator{
Files: files,
MapTasks: make([]Task, len(files)),
ReduceTasks: make([]Task, nReduce),
done: make(chan struct{}),
}
fmt.Printf("Coordinator: MakeCoordinator\n")
fmt.Printf("Coordinator: files %v\n", files)
fmt.Printf("Coordinator: map tasks %v\n", c.MapTasks)
fmt.Printf("Coordinator: reduce tasks %v\n", c.ReduceTasks)
c.startPeriodicChecks() // Detect stuck tasks
c.server() // Start RPC server
return &c
}
startPeriodicChecks()looks for tasks that have been assigned too long without completing — we cover that in section 4. First, the main request path.
2.2. GetTask
Workers fetch work from the Coordinator via RPC: a worker calls GetTask() as if it were a local function.
GetTask uses:
- Request type
GetTaskArgs:
// GetTaskArgs: worker sends no fields when asking for work.
type GetTaskArgs struct{}
- Reply type
GetTaskReply:
// GetTaskReply: task details, or WaitForTask if nothing is ready yet.
type GetTaskReply struct {
InputFileName string // Input file (map tasks only)
Operation string // "map" or "reduce"
OperationNumber int // Task index within the current phase
NMap int // Total map tasks
NReduce int // Total reduce tasks
WaitForTask bool // If true, worker should sleep and retry
}
GetTask must preserve map-then-reduce ordering and avoid duplicate assignment. The logic:
- Prefer map tasks — assign a
NotStartedmap task if any. - If map is not all done → wait — if no map task is free but some maps are still in flight, set
WaitForTask.Reduce starts only after all map tasks complete (including retries).
- Then reduce tasks — when every map is done, assign reduce tasks the same way.
- If reduce is not all done → wait — analogous to map; allows reassignment after failures.
- When everything completes — return a special error so workers exit.
The coordinator holds
muwhile updating task lists to avoid races.
var ErrAllTasksCompleted = fmt.Errorf("all tasks completed")
func (c *Coordinator) GetTask(args *GetTaskArgs, reply *GetTaskReply) error {
c.mu.Lock()
defer c.mu.Unlock()
// 1. Prefer a NotStarted map task.
if i, task := c.findAvailableTask(c.MapTasks); task != nil {
c.assignTask("map", i, task, reply)
return nil
}
// 2. No free map task, but maps not all completed → wait.
if !c.allTasksCompleted(c.MapTasks) {
reply.WaitForTask = true
fmt.Println("No map tasks available, worker should wait")
return nil
}
fmt.Println("All map tasks completed, looking for reduce tasks")
// 3. All maps done → try reduce.
if i, task := c.findAvailableTask(c.ReduceTasks); task != nil {
c.assignTask("reduce", i, task, reply)
return nil
}
// 4. No free reduce, but reduces not all done → wait.
if !c.allTasksCompleted(c.ReduceTasks) {
reply.WaitForTask = true
fmt.Println("No reduce tasks available. Worker should wait for existing reduce tasks to complete.")
return nil
}
// 5. All reduce tasks completed → job done.
fmt.Println("All reduce tasks are completed. All work is done!")
return ErrAllTasksCompleted
}
// findAvailableTask returns the first NotStarted task in tasks.
func (c *Coordinator) findAvailableTask(tasks []Task) (int, *Task) {
for i, task := range tasks {
if task.taskStatus == NotStarted {
return i, &tasks[i]
}
}
return 0, nil
}
// assignTask fills reply and marks the task Assigned.
func (c *Coordinator) assignTask(operation string, index int, task *Task, reply *GetTaskReply) {
reply.Operation = operation
reply.OperationNumber = index
reply.NMap = len(c.MapTasks)
reply.NReduce = len(c.ReduceTasks)
reply.WaitForTask = false
task.taskStatus = Assigned
task.assignedAt = time.Now()
if operation == "map" {
reply.InputFileName = c.Files[index]
}
}
2.3. MarkTaskCompleted
When a worker finishes a map or reduce task, it calls MarkTaskCompleted so the coordinator can update state and eventually finish the job.
// MarkTaskCompletedArgs: what the worker sends on completion.
type MarkTaskCompletedArgs struct {
Operation string // "map" or "reduce"
OperationNumber int // Which task finished
}
type MarkTaskCompletedReply struct{}
func (c *Coordinator) MarkTaskCompleted(args *MarkTaskCompletedArgs, reply *MarkTaskCompletedReply) error {
c.mu.Lock()
defer c.mu.Unlock()
if args.Operation == "map" {
c.MapTasks[args.OperationNumber].taskStatus = Completed
return nil
} else if args.Operation == "reduce" {
c.ReduceTasks[args.OperationNumber].taskStatus = Completed
return nil
}
return fmt.Errorf("invalid operation")
}
3. Worker
With scheduling clear, here is how a worker runs.
3.1. Main worker loop
On startup, a worker repeatedly asks the coordinator for work. For each task (map or reduce):
- Run the user-supplied
mapforreducef. - Report completion.
- Loop until the coordinator signals that there is no more work.
func Worker(mapf func(string, string) []KeyValue, reducef func(string, []string) string) {
for {
task, taskExists := GetTask()
if !taskExists {
break
}
if task.WaitForTask {
time.Sleep(500 * time.Millisecond)
continue
}
if task.Operation == "map" {
handleMapTask(task, mapf)
} else if task.Operation == "reduce" {
handleReduceTask(task, reducef)
} else {
log.Fatalf("unknown operation: %v", task.Operation)
panic(fmt.Errorf("unknown operation: %v", task.Operation))
}
MarkTaskCompleted(task.Operation, task.OperationNumber)
}
}
Notes:
mapfandreducefare user-defined — that is the whole point of the framework.WaitForTaskbacks off briefly, reducing load while other workers finish or fail.
// call performs one RPC to the coordinator and waits for a reply.
// Returns true on success, false on RPC failure.
func call(rpcname string, args interface{}, reply interface{}) bool {
sockname := coordinatorSock()
c, err := rpc.DialHTTP("unix", sockname)
if err != nil {
log.Fatal("dial error:", err)
}
defer c.Close()
err = c.Call(rpcname, args, reply)
if err == nil {
return true
}
fmt.Println(err)
return false
}
func MarkTaskCompleted(operation string, operationNumber int) {
args := MarkTaskCompletedArgs{
Operation: operation,
OperationNumber: operationNumber,
}
reply := MarkTaskCompletedReply{}
ok := call("Coordinator.MarkTaskCompleted", &args, &reply)
if !ok {
fmt.Printf("RPC failed!\n")
}
}
func GetTask() (*GetTaskReply, bool) {
args := GetTaskArgs{}
reply := GetTaskReply{}
ok := call("Coordinator.GetTask", &args, &reply)
if ok {
return &reply, true
}
fmt.Printf("RPC failed!\n")
return nil, false
}
The other important pieces are handleMapTask and handleReduceTask.
3.2. Map task handler
handleMapTask:
- Reads the input file.
- Calls
mapfto produce intermediate key-value pairs. - For each pair, chooses a reduce partition with
ihash(key) % NReduceand buffers lines for intermediate filesmr-X-Y.
func handleMapTask(task *GetTaskReply, mapf func(string, string) []KeyValue) {
fmt.Printf("Map task received...\n")
fmt.Printf("filename: %v\n", task.InputFileName)
fileName := task.InputFileName
contents, err := os.ReadFile(fileName)
if err != nil {
log.Fatalf("cannot read %v", fileName)
panic(err)
}
// User map: filename → intermediate k/v list.
kva := mapf(fileName, string(contents))
filecontentsmap := make(map[string]string)
for _, kv := range kva {
reduceTaskNumberForKey := ihash(kv.Key) % task.NReduce
outputFileName := fmt.Sprintf("mr-%d-%d", task.OperationNumber, reduceTaskNumberForKey)
output := filecontentsmap[outputFileName]
filecontentsmap[outputFileName] = fmt.Sprintf("%s%s %s\n", output, kv.Key, kv.Value)
}
fmt.Printf("Map task completed: %v\n", task.InputFileName)
}
Highlights:
ihash(kv.Key) % task.NReducespreads keys across reduce tasks.mr-X-Y: map taskX, reduce bucketY.- Reduce reads these intermediates next.
3.3. Reduce task handler
Step 1 — read intermediate files
intermediate := []KeyValue{}
for i := 0; i < task.NMap; i++ {
filename := fmt.Sprintf("mr-%d-%d", i, task.OperationNumber)
kva := parseKeyValuePairsFromFile(filename)
fmt.Printf("reduce task %v: got intermediate keys from %v\n", task.OperationNumber, filename)
intermediate = append(intermediate, kva...)
}
Step 2 — sort by key
sort.Sort(ByKey(intermediate))
Step 3 — group and call reducef
for i := 0; i < len(intermediate); {
j := i + 1
for j < len(intermediate) && intermediate[j].Key == intermediate[i].Key {
j++
}
values := []string{}
for k := i; k < j; k++ {
values = append(values, intermediate[k].Value)
}
output := reducef(intermediate[i].Key, values)
// ... write final output (omitted here)
i = j
}
4. Handling worker failures
In a distributed setting, workers can crash, disconnect, or hang. If the coordinator never reassigns those tasks, the job stalls forever.
The coordinator runs a periodic check: if a task stays Assigned too long without MarkTaskCompleted, it resets the task to NotStarted so another worker can take it.
4.1. Periodic checker
We use time.Ticker with a 10-second period:
func (c *Coordinator) startPeriodicChecks() {
ticker := time.NewTicker(10 * time.Second)
go func() {
for {
select {
case <-ticker.C:
c.checkTimeoutsAndReassignTasks()
case <-c.done:
ticker.Stop()
return
}
}
}()
}
4.2. Timeout and reassignment
checkTimeoutsAndReassignTasks scans map and reduce tasks; any Assigned task older than 10 seconds is reset to a zero Task (back to NotStarted):
func (c *Coordinator) checkTimeoutsAndReassignTasks() {
c.mu.Lock()
defer c.mu.Unlock()
for i, task := range c.MapTasks {
if task.taskStatus == Assigned && time.Since(task.assignedAt) > 10*time.Second {
c.MapTasks[i] = Task{}
}
}
for i, task := range c.ReduceTasks {
if task.taskStatus == Assigned && time.Since(task.assignedAt) > 10*time.Second {
c.ReduceTasks[i] = Task{}
}
}
}
That completes a simple but end-to-end MapReduce system in Go.
Conclusion
In this post we walked through MIT 6.5840 Lab 1: a minimal MapReduce framework. We covered the programming model and how coordinator and workers coordinate over RPC — a useful mental model for how distributed systems are structured.
I published my full Lab 1 source on GitHub; I hope it helps you see how the pieces fit together in practice.