MIT 6.5840 là một khóa học nổi tiếng về hệ thống phân tán được giảng dạy tại MIT. Khóa học này bao quát nhiều chủ đề quan trọng trong lĩnh vực hệ thống phân tán như khả năng chịu lỗi (fault tolerance), tính nhất quán (consistency), sao chép dữ liệu (replication) và phân mảnh (sharding). Không chỉ dừng lại ở lý thuyết, khóa học còn đi sâu vào thiết kế và triển khai các hệ thống phân tán thực tế, với các ví dụ tiêu biểu như MapReduce, Raft và ZooKeeper.
Trong loạt bài viết này, tôi sẽ ghi lại quá trình học và những kiến thức thu nhận được từ các bài giảng và bài lab của khóa học. Đây sẽ là tài liệu tham khảo cho chính tôi và những ai đang quan tâm đến lĩnh vực hệ thống phân tán.
Ở bài viết này, chúng ta sẽ cùng tìm hiểu Lab 1 của MIT 6.5840 – nơi bạn sẽ được tự tay xây dựng một framework MapReduce đơn giản.
1. MapReduce là gì?
MapReduce là một mô hình lập trình rất phổ biến, giúp chúng ta dễ dàng xử lý các tập dữ liệu lớn bằng cách chia nhỏ công việc và thực thi song song. Đây là một phương pháp hiệu quả để tăng tốc độ xử lý khi làm việc với dữ liệu quy mô lớn. Bài báo gốc của Jeff Dean và Sanjay Ghemawat - MapReduce: Simplified Data Processing on Large Clusters - là một tài liệu rất đáng đọc, nhưng ở đây mình sẽ tóm tắt lại những điểm chính, rồi chia sẻ cách mình đã triển khai nó.
Chúng ta sẽ cùng tìm hiểu mô hình này qua một ví dụ đơn giản trong bài báo: đếm số lần xuất hiện của từng từ. Giả sử bạn có một tập hợp lớn các tệp văn bản, và nhiệm vụ là đếm xem mỗi từ xuất hiện bao nhiêu lần. Để làm được điều này với MapReduce, bạn chỉ cần định nghĩa hai hàm: map và reduce, sau đó đưa chúng vào framework MapReduce để nó lo phần còn lại.
1.1. Hàm Map
// KeyValue là kiểu dữ liệu biểu diễn một cặp key-value.
type KeyValue struct {
Key string
Value string
}
// Map được gọi một lần cho mỗi tệp đầu vào.
func Map(filename string, contents string) []KeyValue {
// Hàm xác định đâu là ký tự ngăn cách giữa các từ.
ff := func(r rune) bool { return !unicode.IsLetter(r) }
// Tách nội dung văn bản thành các từ, dùng hàm ff để loại bỏ dấu câu, số, v.v.
words := strings.FieldsFunc(contents, ff)
kva := []KeyValue{}
for _, w := range words {
// Với mỗi từ tìm được, tạo một cặp key-value
// trong đó key là từ và value là "1".
kv := KeyValue{w, "1"}
kva = append(kva, kv)
}
return kva
}
Giải thích: Hàm Map sẽ được framework gọi cho mỗi tệp đầu vào.
- Tham số filename là tên tệp (trong ví dụ này không dùng đến).
- Tham số contents là toàn bộ nội dung của tệp dưới dạng chuỗi.
- Mục tiêu của hàm là: tách nội dung thành từng từ, rồi tạo ra một cặp (từ, “1”) cho mỗi từ.
Ví dụ: Giả sử nội dung tệp là:
Go is expressive, concise, clean, and efficient.
Thì kết quả trả về sẽ là:
[]KeyValue{
{"Go", "1"},
{"is", "1"},
{"expressive", "1"},
{"concise", "1"},
{"clean", "1"},
{"and", "1"},
{"efficient", "1"},
}
Các cặp key-value này sau đó sẽ được gửi đến các node reduce để cộng tổng số lần xuất hiện của mỗi từ.
1.2. Hàm Reduce
// Reduce được gọi một lần cho mỗi từ (key) duy nhất.
func Reduce(key string, values []string) string {
// Trả về tổng số lần xuất hiện của từ này dưới dạng chuỗi.
return strconv.Itoa(len(values))
}
Giải thích: Hàm Reduce sẽ được gọi một lần cho mỗi từ duy nhất (tức là mỗi key) mà các tác vụ Map đã tạo ra.
- Tham số key là từ cần xử lý.
- Tham số values là một danh sách chứa tất cả các giá trị “1” mà hàm Map đã phát ra cho từ đó.
Vì mỗi lần Map gặp từ nào đó, nó tạo ra cặp (“từ”, “1”), nên chiều dài của danh sách values tương ứng với số lần từ đó xuất hiện trong toàn bộ dữ liệu.
Ví dụ: Nếu từ “Go” xuất hiện 5 lần trong tất cả các tệp, thì khi gọi:
Reduce("Go", []string{"1", "1", "1", "1", "1"})
Hàm sẽ trả về chuỗi “5”, nghĩa là từ “Go” xuất hiện 5 lần.
1.3. Framework MapReduce sử dụng các hàm này như thế nào?
Chúng ta chỉ cần cung cấp hai hàm map và reduce cho framework MapReduce. Phần còn lại sẽ được framework xử lý tự động. Trong hệ thống này có hai thành phần chính:
- Coordinator: quản lý toàn bộ quá trình.
- Workers: thực hiện các tác vụ map và reduce.
Quy trình hoạt động diễn ra như sau:
- Giai đoạn Map:
- Coordinator chia dữ liệu đầu vào thành M phần nhỏ (splits).
- Mỗi phần sẽ được giao cho một worker, worker này gọi hàm map để xử lý dữ liệu.
- Hàm map sẽ trả về các cặp key-value trung gian. Các cặp này được chia thành R phần (tương ứng với số worker thực hiện reduce) và lưu xuống ổ đĩa.
- Chuyển sang Reduce:
- Sau khi tất cả các tác vụ map hoàn tất, coordinator bắt đầu gán các tác vụ reduce cho các worker.
- Mỗi worker reduce sẽ:
- Đọc toàn bộ dữ liệu trung gian liên quan đến phần việc của mình từ ổ đĩa.
- Sắp xếp lại theo key để gom tất cả các giá trị của cùng một từ vào một nhóm.
- Gọi hàm reduce với key và danh sách các values tương ứng.
- Ghi kết quả cuối cùng ra ổ đĩa.
- Hoàn tất:
- Khi tất cả các tác vụ map và reduce đều hoàn thành, các worker sẽ dừng lại.
- Lúc này chương trình có thể thông báo rằng quá trình xử lý đã hoàn tất.
Dưới đây là sơ đồ minh họa quy trình hoạt động của framework MapReduce, giúp bạn dễ hình dung cách các thành phần phối hợp với nhau từ giai đoạn Map đến giai đoạn Reduce.
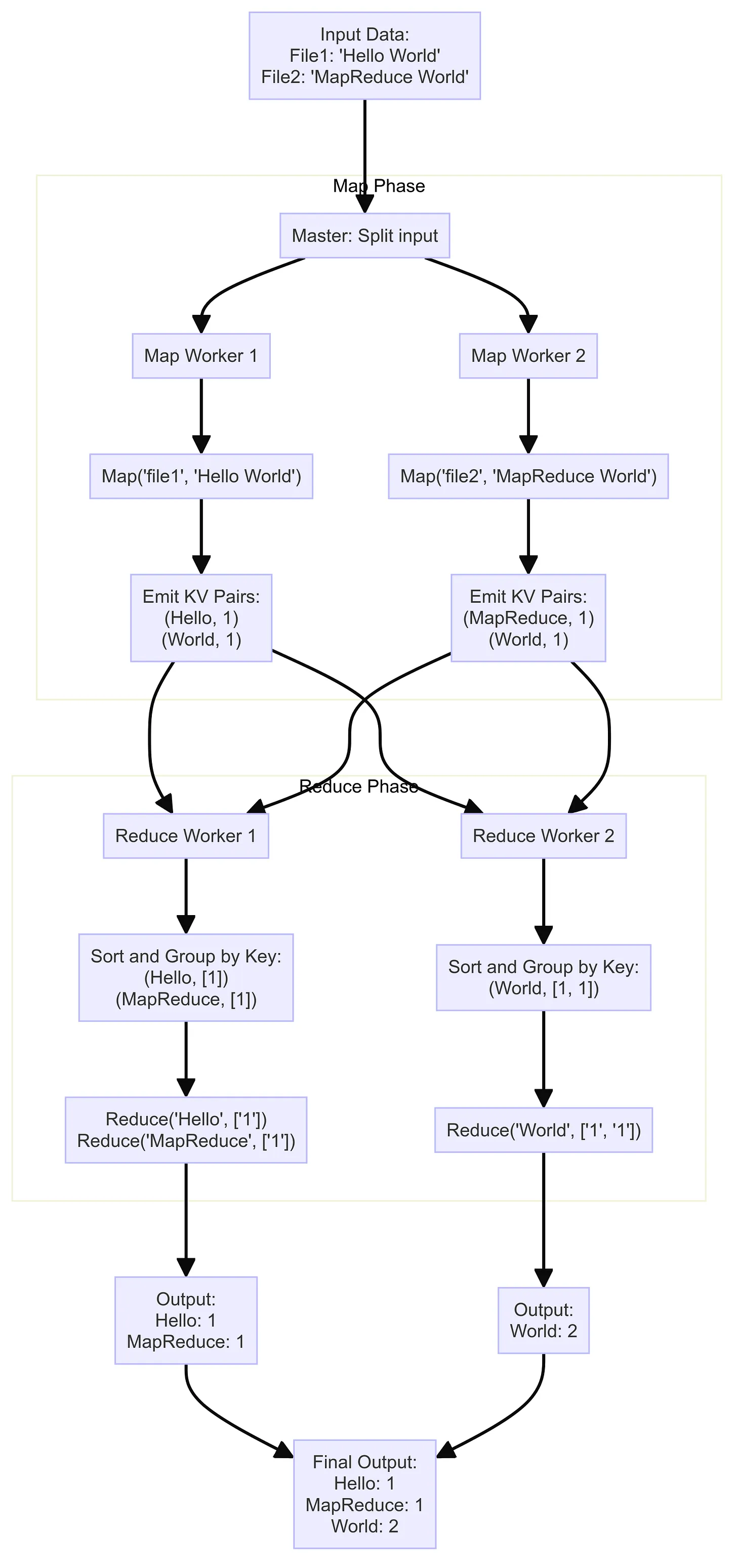
2. Cách triển khai
(Lưu ý: Đây chưa phải là phiên bản code tối ưu nhất, vẫn còn nhiều chỗ có thể cải thiện. Tuy nhiên, ở bản đầu tiên này, mình ưu tiên giữ cho nó dễ đọc và dễ hiểu.)
Toàn bộ mã nguồn nằm trong hai tệp coordinator.go và worker.go. Vì mục đích hiện tại chỉ là học tập, nên chúng ta giả định rằng cả coordinator và worker đều chạy trên cùng một máy.
2.1. Coordinator
Trước tiên, chúng ta cần định nghĩa hai cấu trúc quan trọng: Task và Coordinator.
// TaskStatus biểu thị trạng thái hiện tại của một Task.
type TaskStatus int
const (
NotStarted TaskStatus = iota // Chưa bắt đầu
Assigned // Đã được giao
Completed // Đã hoàn thành
)
// Task theo dõi trạng thái và thời điểm được giao cho worker.
type Task struct {
taskStatus TaskStatus
assignedAt time.Time
}
// Coordinator điều phối các tác vụ Map và Reduce.
type Coordinator struct {
mu sync.Mutex
Files []string
MapTasks []Task
ReduceTasks []Task
done chan struct{}
}
Giải thích:
- Mỗi Task đại diện cho một đơn vị công việc. Nó lưu trạng thái hiện tại (
NotStarted,Assigned, hoặcCompleted) và thời điểm nó được giao cho một worker (assignedAt). Việc theo dõi thời gian này giúp coordinator phát hiện và gán lại các tác vụ nếu worker không phản hồi kịp thời. - Cấu trúc
Coordinatorlà trung tâm quản lý toàn bộ quá trình xử lý. Nó bao gồm:mu: Một mutex để bảo vệ truy cập đồng thời tới dữ liệu dùng chung.Files: Danh sách các tệp đầu vào sẽ được xử lý.MapTasks: Slice chứa tất cả các tác vụ map.ReduceTasks: Slice chứa tất cả các tác vụ reduce.done: Channel dùng để thông báo khi tất cả công việc đã hoàn tất.
2.1.1. Thiết lập RPC server
Để giao tiếp với các worker, Coordinator sử dụng cơ chế RPC (Remote Procedure Call). Dưới đây là phương thức server() dùng để thiết lập một RPC server:
// server thiết lập một máy chủ RPC để lắng nghe các worker.
func (c *Coordinator) server() {
rpc.Register(c)
rpc.HandleHTTP()
sockname := coordinatorSock()
os.Remove(sockname)
l, e := net.Listen("unix", sockname)
if e != nil {
log.Fatal("listen error:", e)
}
go http.Serve(l, nil)
}
Phương thức này tạo một socket Unix và khởi chạy một HTTP server để lắng nghe và xử lý các yêu cầu RPC gửi từ các worker.
2.1.2. Hàm khởi tạo Coordinator
Hàm MakeCoordinator() khởi tạo một đối tượng Coordinator, tạo các tác vụ map/reduce dựa trên số lượng tệp đầu vào và số lượng reduce task mong muốn, sau đó khởi động RPC server
// MakeCoordinator tạo một Coordinator mới.
func MakeCoordinator(files []string, nReduce int) *Coordinator {
c := Coordinator{
Files: files,
MapTasks: make([]Task, len(files)),
ReduceTasks: make([]Task, nReduce),
done: make(chan struct{}),
}
fmt.Printf("Coordinator: MakeCoordinator\n")
fmt.Printf("Coordinator: files %v\n", files)
fmt.Printf("Coordinator: map tasks %v\n", c.MapTasks)
fmt.Printf("Coordinator: reduce tasks %v\n", c.ReduceTasks)
c.startPeriodicChecks() // Kiểm tra định kỳ các tác vụ bị treo
c.server() // Khởi động RPC server
return &c
}
Hàm
startPeriodicChecks()sẽ kiểm tra xem có task nào bị “timeout” không — tức là đã giao cho worker nhưng lâu quá chưa xử lý xong. Chúng ta sẽ tìm hiểu kỹ hơn về chức năng này sau. Trước hết, hãy cùng đi tiếp để hiểu luồng xử lý chính của hệ thống.
2.2. GetTask
Để các Worker có thể nhận và thực hiện công việc được giao từ Coordinator, chúng ta sử dụng RPC (Remote Procedure Call) – một phương pháp cho phép một tiến trình (Worker) gọi một hàm trên một tiến trình khác (Coordinator) như thể đó là một lời gọi hàm cục bộ.
Cụ thể, mỗi Worker sẽ khởi tạo một RPC call tới hàm GetTask() được expose bởi Coordinator để yêu cầu một nhiệm vụ mới.
Hàm GetTask() có cấu trúc như sau:
- Đối số đầu vào (
GetTaskArgs):// GetTaskArgs: Worker không cần gửi thông tin gì khi yêu cầu một công việc mới. type GetTaskArgs struct{} - Kết quả phản hồi (
GetTaskReply):// GetTaskReply: Coordinator trả về thông tin chi tiết về nhiệm vụ được giao, // hoặc chỉ thị cho Worker chờ đợi nếu không có nhiệm vụ sẵn sàng. type GetTaskReply struct { InputFileName string // Tên tệp đầu vào cần xử lý (chỉ có giá trị cho nhiệm vụ "map") Operation string // Loại nhiệm vụ: "map" hoặc "reduce" OperationNumber int // Số thứ tự duy nhất của nhiệm vụ trong phase hiện tại (map hoặc reduce) NMap int // Tổng số nhiệm vụ "map" trong toàn bộ quá trình NReduce int // Tổng số nhiệm vụ "reduce" trong toàn bộ quá trình WaitForTask bool // Nếu true, Worker không được giao nhiệm vụ và nên tạm thời chờ trước khi thử lại }Hàm
GetTasktrong Coordinator chịu trách nhiệm phân công công việc cho các worker, đảm bảo tiến trình diễn ra theo đúng thứ tự (map trước, reduce sau) và tránh trùng lặp công việc. Dưới đây là các bước chính:
Việc triển khai phương thức GetTask cũng khá đơn giản.
-
Ưu tiên nhiệm vụ map Coordinator sẽ tìm một nhiệm vụ
mapchưa bắt đầu và giao ngay cho worker. - Nếu map chưa xong hết → worker đợi
Khi không còn nhiệm vụ map mới, nhưng vẫn còn một số đang chạy, coordinator yêu cầu worker tạm thời chờ.
Việc chuyển sang
reducechỉ diễn ra sau khi tất cảmapđã hoàn thành. -
Chuyển sang nhiệm vụ reduce Khi mọi nhiệm vụ
mapđã xong, coordinator bắt đầu tìm và giao các nhiệm vụreduce. - Nếu reduce chưa xong hết → worker tiếp tục đợi
Tương tự như
map, nếu các nhiệm vụreduceđã được giao nhưng chưa hoàn thành hết, worker được yêu cầu đợi.Điều này đảm bảo rằng nếu có worker thất bại, coordinator có thể gán lại nhiệm vụ cho worker khác.
- Khi mọi thứ hoàn tất
Nếu tất cả các nhiệm vụ
reduceđã hoàn thành, coordinator sẽ báo hiệu rằng quá trình MapReduce đã kết thúc.Lưu ý: Coordinator sử dụng mutex (khóa) để đảm bảo an toàn khi nhiều worker cùng lúc yêu cầu nhiệm vụ. Điều này giúp tránh xung đột dữ liệu (race condition) khi cập nhật danh sách các công việc map và reduce.
var ErrAllTasksCompleted = fmt.Errorf("all tasks completed")
func (c *Coordinator) GetTask(args *GetTaskArgs, reply *GetTaskReply) error {
c.mu.Lock()
defer c.mu.Unlock()
// 1. Ưu tiên tìm kiếm và gán nhiệm vụ "map" chưa được bắt đầu.
// Nếu tìm thấy, gán nhiệm vụ, điền thông tin vào `reply` và kết thúc.
if i, task := c.findAvailableTask(c.MapTasks); task != nil {
c.assignTask("map", i, task, reply)
return nil
}
// 2. Nếu không còn nhiệm vụ "map" nào để gán, nhưng tất cả nhiệm vụ "map" chưa hoàn tất:
// Yêu cầu Worker chờ đợi. Điều này là quan trọng vì pha "reduce" chỉ có thể bắt đầu
// khi tất cả nhiệm vụ "map" đã hoàn thành (bao gồm cả việc xử lý lại các tác vụ thất bại).
if !c.allTasksCompleted(c.MapTasks) {
reply.WaitForTask = true
fmt.Println("No map tasks available, worker should wait")
return nil
}
fmt.Println("All map tasks completed, looking for reduce tasks")
// 3. Nếu tất cả nhiệm vụ "map" đã hoàn tất, tiếp tục tìm kiếm và gán nhiệm vụ "reduce" chưa được bắt đầu.
// Nếu tìm thấy, gán nhiệm vụ, điền thông tin vào `reply` và kết thúc.
if i, task := c.findAvailableTask(c.ReduceTasks); task != nil {
c.assignTask("reduce", i, task, reply)
return nil
}
// 4. Nếu tất cả nhiệm vụ "reduce" đã được gán, nhưng chưa hoàn tất:
// Yêu cầu Worker chờ đợi. Điều này bao gồm cả việc chờ các Worker khác hoàn thành
// hoặc chờ các tác vụ đã gán bị timeout/thất bại để được gán lại.
if !c.allTasksCompleted(c.ReduceTasks) {
reply.WaitForTask = true
fmt.Println("No reduce tasks available. Worker should wait for existing reduce tasks to complete.")
return nil // Yêu cầu worker chờ
}
// 5. Nếu tất cả nhiệm vụ "reduce" đã hoàn thành:
// Điều này có nghĩa là toàn bộ quá trình MapReduce đã hoàn tất.
// Coordinator trả về một lỗi đặc biệt để thông báo trạng thái này.
fmt.Println("All reduce tasks are completed. All work is done!")
return ErrAllTasksCompleted
}
// findAvailableTask: Tìm kiếm một tác vụ có trạng thái `NotStarted` trong slice `tasks` đã cho.
// Trả về chỉ số và con trỏ tới tác vụ tìm thấy, hoặc (0, nil) nếu không có tác vụ nào.
func (c *Coordinator) findAvailableTask(tasks []Task) (int, *Task) {
for i, task := range tasks {
if task.taskStatus == NotStarted {
return i, &tasks[i]
}
}
return 0, nil
}
// assignTask: Gán thông tin nhiệm vụ vào `GetTaskReply` và cập nhật trạng thái của nhiệm vụ trong Coordinator.
func (c *Coordinator) assignTask(operation string, index int, task *Task, reply *GetTaskReply) {
reply.Operation = operation
reply.OperationNumber = index
reply.NMap = len(c.MapTasks)
reply.NReduce = len(c.ReduceTasks)
reply.WaitForTask = false
// Cập nhật trạng thái của tác vụ trong Coordinator.
task.taskStatus = Assigned
task.assignedAt = time.Now()
// Đối với nhiệm vụ "map", cần cung cấp tên tệp đầu vào.
if operation == "map" {
reply.InputFileName = c.Files[index]
}
}
2.3. MarkTaskCompleted
Khi một worker hoàn thành nhiệm vụ được giao (dù là map hay reduce), nó sẽ gọi hàm RPC MarkTaskCompleted để thông báo cho coordinator.
Hàm này giúp coordinator cập nhật trạng thái nhiệm vụ, từ đó biết được khi nào có thể chuyển giai đoạn (ví dụ: từ map sang reduce), hoặc kết thúc toàn bộ tiến trình.
// Đối số mà worker gửi khi hoàn thành nhiệm vụ
type MarkTaskCompletedArgs struct {
Operation string // "map" hoặc "reduce"
OperationNumber int // Số thứ tự nhiệm vụ đã hoàn thành
}
// Phản hồi từ Coordinator (trống trong trường hợp này)
type MarkTaskCompletedReply struct{}
func (c *Coordinator) MarkTaskCompleted(args *MarkTaskCompletedArgs, reply *MarkTaskCompletedReply) error {
c.mu.Lock()
defer c.mu.Unlock()
if args.Operation == "map" {
// Đánh dấu nhiệm vụ map đã hoàn thành
c.MapTasks[args.OperationNumber].taskStatus = Completed
return nil
} else if args.Operation == "reduce" {
// Đánh dấu nhiệm vụ reduce đã hoàn thành
c.ReduceTasks[args.OperationNumber].taskStatus = Completed
return nil
}
// Trường hợp không hợp lệ (operation không phải "map" hoặc "reduce")
return fmt.Errorf("invalid operation")
}
3. Worker
Sau khi đã hiểu cách Coordinator phân công nhiệm vụ, giờ ta sẽ tìm hiểu cách một worker hoạt động.
3.1. Luồng hoạt động chính của worker
Khi khởi động, một worker sẽ bắt đầu gửi yêu cầu đến coordinator để xin việc. Khi được giao một nhiệm vụ (dạng map hoặc reduce), worker sẽ:
- Thực hiện nhiệm vụ đó bằng các hàm xử lý người dùng cung cấp (mapf hoặc reducef).
- Gửi lại kết quả thông báo rằng mình đã hoàn thành.
- Tiếp tục vòng lặp: xin nhiệm vụ mới → thực hiện → báo hoàn thành → lặp lại.
Quá trình này tiếp diễn cho đến khi coordinator thông báo rằng không còn việc để làm.
func Worker(mapf func(string, string) []KeyValue, reducef func(string, []string) string) {
for {
// Yêu cầu một tác vụ từ coordinator
task, taskExists := GetTask()
if !taskExists {
// Nếu không có tác vụ nào, thoát vòng lặp
break
}
if task.WaitForTask {
// Nếu được yêu cầu chờ, nghỉ 0.5s rồi thử lại
time.Sleep(500 * time.Millisecond)
continue
}
// Gọi hàm tương ứng với loại nhiệm vụ
if task.Operation == "map" {
handleMapTask(task, mapf)
} else if task.Operation == "reduce" {
handleReduceTask(task, reducef)
} else {
log.Fatalf("unknown operation: %v", task.Operation)
panic(fmt.Errorf("unknown operation: %v", task.Operation))
}
// Gửi thông báo đã hoàn thành nhiệm vụ
MarkTaskCompleted(task.Operation, task.OperationNumber)
}
}
Một số điểm cần lưu ý:
- Các hàm
mapfvàreduceflà các hàm do người dùng tự định nghĩa. Đây là điểm chính của framework. - Nếu chưa có công việc mới, worker sẽ được yêu cầu tạm thời chờ. Cơ chế này giúp giảm tải cho hệ thống và tạo điều kiện để các nhiệm vụ đang chờ (ví dụ do worker khác bị lỗi) có thể được phân công lại một cách hiệu quả.
// call gửi một yêu cầu RPC đến coordinator và đợi phản hồi.
// thường trả về true.
// trả về false nếu có lỗi xảy ra.
func call(rpcname string, args interface{}, reply interface{}) bool {
sockname := coordinatorSock()
c, err := rpc.DialHTTP("unix", sockname)
if err != nil {
log.Fatal("lỗi quay số:", err)
}
defer c.Close()
err = c.Call(rpcname, args, reply)
if err == nil {
return true
}
fmt.Println(err)
return false
}
// Gọi RPC để báo hoàn thành nhiệm vụ
func MarkTaskCompleted(operation string, operationNumber int) {
args := MarkTaskCompletedArgs{
Operation: operation,
OperationNumber: operationNumber,
}
reply := MarkTaskCompletedReply{}
ok := call("Coordinator.MarkTaskCompleted", &args, &reply)
if !ok {
fmt.Printf("lệnh gọi thất bại!\n")
}
}
// Gọi RPC để xin nhiệm vụ từ Coordinator
func GetTask() (*GetTaskReply, bool) {
args := GetTaskArgs{}
reply := GetTaskReply{}
ok := call("Coordinator.GetTask", &args, &reply)
if ok {
return &reply, true
} else {
fmt.Printf("lệnh gọi thất bại!\n")
return nil, false
}
}
Hai phần quan trọng khác của worker là handleMapTask và handleReduceTask. Như tên gọi, chúng xử lý các tác vụ map và reduce tương ứng.
3.2. Trình xử lý tác vụ Map
Hàm handleMapTask là nơi Worker thực hiện một tác vụ kiểu Map. Cụ thể, Worker sẽ:
- Đọc nội dung từ tệp đầu vào.
- Gọi hàm
mapf(do người dùng định nghĩa) để xử lý nội dung đó và tạo ra danh sách các cặp key-value trung gian. - Với mỗi cặp key-value, xác định nó nên được gửi đến tác vụ
reducenào, rồi ghi chúng vào các tệp trung gian tương ứng.
func handleMapTask(task *GetTaskReply, mapf func(string, string) []KeyValue) {
fmt.Printf("Map task received...\n")
fmt.Printf("filename: %v\n", task.InputFileName)
fileName := task.InputFileName
// Đọc nội dung tệp đầu vào
contents, err := os.ReadFile(fileName)
if err != nil {
log.Fatalf("cannot read %v", fileName)
panic(err)
}
// Gọi hàm map do người dùng cung cấp.
// Key: tên tệp, Value: nội dung tệp.
kva := mapf(fileName, string(contents))
filecontentsmap := make(map[string]string)
for _, kv := range kva {
// Xác định tác vụ reduce sẽ xử lý key này
reduceTaskNumberForKey := ihash(kv.Key) % task.NReduce
// Tạo tên file trung gian: mr-mapTaskID-reduceTaskID
outputFileName := fmt.Sprintf("mr-%d-%d", task.OperationNumber, reduceTaskNumberForKey)
output := filecontentsmap[outputFileName]
// Thêm nội dung vào file tương ứng
filecontentsmap[outputFileName] = fmt.Sprintf("%s%s %s\n", output, kv.Key, kv.Value)
}
// Ghi nội dung vào các file trung gian
fmt.Printf("Map task completed: %v\n", task.InputFileName)
}
Những điểm quan trọng:
mapf(fileName, string(contents)): Gọi hàm map để biến nội dung tệp thành các cặp key-value trung gian.ihash(kv.Key) % task.NReduce: Với mỗi key, tính toán tác vụ reduce sẽ xử lý nó. Điều này giúp phân chia dữ liệu đều giữa các worker reduce.mr-X-Y: Là tên file trung gian chứa kết quả từ tác vụ map thứX, dành cho tác vụ reduce thứY.- Cuối cùng, các file trung gian này sẽ được sử dụng trong bước Reduce sau này.
3.3. Trình xử lý tác vụ Reduce
Khi đến giai đoạn Reduce, mỗi worker sẽ đảm nhiệm một tác vụ Reduce cụ thể. Mục tiêu là tổng hợp tất cả các cặp key-value trung gian tương ứng, sau đó xử lý chúng bằng hàm reduce mà người dùng đã cung cấp.
Bước 1: Đọc toàn bộ dữ liệu trung gian Worker cần đọc tất cả các tệp đầu vào liên quan đến tác vụ reduce hiện tại. Mỗi tệp trung gian được tạo ra bởi một tác vụ map trước đó.
intermediate := []KeyValue{}
// Đọc tất cả các tệp trung gian cho tác vụ reduce này
for i := 0; i < task.NMap; i++ {
filename := fmt.Sprintf("mr-%d-%d", i, task.OperationNumber)
kva := parseKeyValuePairsFromFile(filename)
fmt.Printf("reduce task %v: got intermediate keys from %v\n", task.OperationNumber, filename)
intermediate = append(intermediate, kva...)
}
mr-X-Y: là tên tệp trung gian, trong đóXlà ID của tác vụ Map,Ylà ID của tác vụ Reduce hiện tại.- Tất cả các cặp key-value trung gian từ các Map worker sẽ được gom lại vào slice intermediate.
Bước 2: Sắp xếp các key-value theo key Để chuẩn bị gọi hàm reduce, ta cần gom nhóm các cặp theo từng key giống nhau. Việc này được thực hiện bằng cách sắp xếp danh sách intermediate.
sort.Sort(ByKey(intermediate))
Bước 3: Gom nhóm và gọi hàm Reduce
Sau khi sắp xếp, ta duyệt qua intermediate để nhóm tất cả các value có cùng key, rồi truyền vào hàm reducef.
for i := 0; i < len(intermediate); {
// Xác định phạm vi các phần tử có cùng key
j := i + 1
for j < len(intermediate) && intermediate[j].Key == intermediate[i].Key {
j++
}
// Gom tất cả các value lại thành một danh sách
values := []string{}
for k := i; k < j; k++ {
values = append(values, intermediate[k].Value)
}
// Gọi hàm reduce do người dùng định nghĩa
output := reducef(intermediate[i].Key, values)
// ... ghi kết quả đầu ra vào tệp (phần này chưa hiển thị ở đây)
i = j // tiếp tục với key tiếp theo
}
4. Xử lý lỗi Worker
Trong một hệ thống phân tán, không thể đảm bảo rằng mọi worker luôn hoạt động ổn định. Có thể một worker bị lỗi, ngắt kết nối hoặc treo máy trong khi đang thực hiện tác vụ. Nếu coordinator không xử lý điều này, tác vụ đó sẽ không bao giờ hoàn thành và hệ thống sẽ bị kẹt mãi mãi.
Để khắc phục, coordinator duy trì một luồng kiểm tra định kỳ: nếu một tác vụ đã được giao quá lâu mà chưa được đánh dấu là hoàn thành, coordinator sẽ coi như worker đó đã thất bại và đánh dấu lại tác vụ là chưa bắt đầu, để nó có thể được giao lại cho một worker khác.
4.1. Tạo luồng kiểm tra định kỳ
Chúng ta sử dụng time.Ticker để thực hiện kiểm tra sau mỗi khoảng thời gian cố định (ở đây là 10 giây):
func (c *Coordinator) startPeriodicChecks() {
ticker := time.NewTicker(10 * time.Second)
go func() {
for {
select {
case <-ticker.C:
// Kiểm tra timeout và reset các tác vụ nếu cần
c.checkTimeoutsAndReassignTasks()
case <-c.done:
// Khi hệ thống kết thúc, dừng kiểm tra
ticker.Stop()
return
}
}
}()
}
4.2. Hàm kiểm tra timeout và gán lại tác vụ
Hàm checkTimeoutsAndReassignTasks sẽ duyệt qua tất cả các tác vụ Map và Reduce, và nếu phát hiện tác vụ nào đã được gán nhưng vẫn chưa hoàn thành sau một khoảng thời gian (ví dụ: 10 giây), nó sẽ đặt lại trạng thái của tác vụ đó, sẵn sàng để giao lại.
func (c *Coordinator) checkTimeoutsAndReassignTasks() {
c.mu.Lock()
defer c.mu.Unlock()
// Kiểm tra các tác vụ Map
for i, task := range c.MapTasks {
if task.taskStatus == Assigned && time.Since(task.assignedAt) > 10*time.Second {
c.MapTasks[i] = Task{} // đặt lại trạng thái = NotStarted
}
}
// Kiểm tra các tác vụ Reduce
for i, task := range c.ReduceTasks {
if task.taskStatus == Assigned && time.Since(task.assignedAt) > 10*time.Second {
c.ReduceTasks[i] = Task{}
}
}
}
Vậy là chúng ta đã hoàn thiện một phiên bản đơn giản nhưng đầy đủ chức năng của hệ thống MapReduce bằng Go!
Lời kết
Qua bài viết này, chúng ta đã cùng nhau tìm hiểu và thảo luận về Lab 1 của khóa học MIT 6.5840, nơi giới thiệu cách xây dựng một framework MapReduce đơn giản. Chúng ta đã tìm hiểu về mô hình lập trình MapReduce, cách các tiến trình coordinator và worker phối hợp thông qua giao thức RPC - tất cả đều giúp chúng ta hình dung rõ hơn về cách một hệ thống phân tán vận hành.
Mình đã chia sẻ toàn bộ mã nguồn của Lab 1 trên GitHub, hy vọng nó sẽ giúp bạn hiểu rõ hơn về cách hoạt động của hệ thống và từng bước triển khai trong thực tế.