Leaderboards are everywhere—in mobile games, esports, and fitness apps. In this post we explore how to design a real-time leaderboard that feels instant for users and stays sane under load. We’ll walk through requirements clarification, load estimation, why a relational database alone fails, Redis Sorted Sets, a full event-driven pipeline with throttling and checksums, and how to scale and recover when things grow or break.
At the surface, a leaderboard is just a sorted list. The fun part is making it real-time without overloading the database or flooding the UI—and knowing when to add a message queue, throttling, caching, sharding, or tie-breaking rules. We’ll give you one coherent story you can adapt to your own scale.
Designing a Real-Time Leaderboard: From Requirements to Scale
Ever wondered how games show the top 10 players updating live without the app freezing or the backend melting? It might seem simple—just sort by score and send the list. The catch is that “sort by score” on a table with hundreds of millions of rows is exactly what you don’t want to do on every refresh. The solution is to stop sorting at read time and use a data structure that is already sorted, plus a pipeline that decouples writes from reads and avoids pushing thousands of updates per second to the client.
Our goal here is to give you one unified narrative: we’ll clarify requirements (including in an interview-style Q&A), estimate load, design the API, discuss security and when to use a message queue, see why a relational database alone fails, introduce Redis Sorted Sets and storage sizing, then build a seven-step flow from game events to WebSocket delivery. After that we’ll cover scaling (sharding strategies), tie-breaking, recovery, and extensions like rank, neighbors, and friend leaderboards.
Every real-time leaderboard has to balance three things:
- Throughput — Ingest score updates at high rate without blocking the game or losing events.
- Ranking — Answer “who are the top K?” (and optionally “what is my rank?”) in logarithmic or constant time, not full table scans.
- Live UX — Push updates to the UI in a way that feels real-time but doesn’t overwhelm the client or the backend.
Let’s dive in.
1. Scope and Requirements: Clarifying What We’re Building
Before jumping into architecture, it pays to nail down the scope. Below is a concise way to clarify requirements—similar to what you’d do in a system design interview.
Candidate: How is the score calculated for the leaderboard?
Interviewer: Each time the user wins a match, we add a point to their total score. Simple point system.
Candidate: Are all players included in the leaderboard?
Interviewer: Yes.
Candidate: Is there a time segment associated with the leaderboard?
Interviewer: Each month a new tournament starts, so we have a new leaderboard per month.
Candidate: What do we need to display?
Interviewer: The top 10 users, plus the rank of a specific user. If time allows, we can also return users a few places above and below a given user.
Candidate: How many users are we talking about?
Interviewer: On the order of 5 million daily active users (DAU) and 25 million monthly active users (MAU). Each player plays on average about 10 matches per day.
Candidate: How do we break ties when two players have the same score?
Interviewer: For now they share the same rank. We can later add tie-breaking (e.g. who reached that score first).
Candidate: Does the leaderboard need to be real-time?
Interviewer: Yes. We want updates as close to real-time as possible; batched history is not acceptable.
From this conversation we get clear functional and non-functional requirements.
Functional requirements:
- Display the top 10 players on the leaderboard.
- Show a given user’s rank.
- (Bonus) Display a small window of players above and below a user (e.g. 4 above, 4 below).
Non-functional requirements:
- Real-time (or near real-time) score updates.
- Leaderboard reflects score changes in real time for the UI.
- Scalability, availability, and reliability in line with the estimated load.
To keep the first version tractable, we’ll focus on:
| Aspect | Choice |
|---|---|
| Scale (example) | 50M registered users, 10M DAU (or 5M DAU / 25M MAU depending on scenario) |
| Display | Top 10 + one user’s rank (neighbors as bonus) |
| Consistency | Eventual |
| Durability | Every score must be persisted and recoverable |
2. Back-of-the-Envelope Estimation
We need a ballpark for requests per second so we can choose synchronous vs asynchronous writes and throttle intervals.
User and score load:
- Average users per second ≈ DAU / (24 × 60 × 60). For 5M DAU that’s about 50 users/s; for 10M DAU about 115 users/s. Traffic is rarely uniform—assume a peak multiplier (e.g. 5× or 10×). So we might plan for 250 users/s (5M DAU) or 1,150 users/s (10M DAU with 10× peak).
- Score update QPS: If each user plays ~10 matches per day and we assume a fraction of those are wins that affect the leaderboard, we can estimate score QPS. For example: 50 users/s × 10 ≈ 500 score QPS average, and with a 5× peak that’s 2,500 score QPS.
- Top-10 read QPS: If each user opens the game once per day and the top 10 is loaded on open, top-10 QPS is on the order of the user arrival rate (e.g. ~50 QPS for 5M DAU).
So the system must handle thousands of score events per second at peak without backpressure, and serve tens to low hundreds of top-10 reads per second. That motivates:
- Asynchronous ingestion (e.g. Kafka) so the game doesn’t wait on the database.
- Throttling when pushing to the UI—sending thousands of updates per second to every client would overwhelm the browser and the network; we’ll push at most a few times per second (e.g. every 500 ms) and only when the top 10 actually changes.
3. API Design
A clear API keeps the contract between clients, game servers, and the leaderboard service explicit.
POST /v1/scores (internal — only game servers)
Updates a user’s score when they win a game. The client must never call this directly; only the game backend should, so scores cannot be forged by the client.
| Field | Description |
|---|---|
| user_id | The user who won the game. |
| points | The number of points to add (e.g. 1 per win). |
Response: 200 OK on success, 400 Bad Request on failure.
GET /v1/scores
Returns the top 10 players.
Sample response:
{
"data": [
{ "user_id": "user_id1", "user_name": "alice", "rank": 1, "score": 12543 },
{ "user_id": "user_id2", "user_name": "bob", "rank": 2, "score": 11500 }
],
"total": 10
}
GET /v1/scores/{user_id}
Returns the rank and score of a specific user.
Sample response:
{
"user_info": {
"user_id": "user5",
"score": 1000,
"rank": 6
}
}
4. Security: Who Updates the Score?
An alternative design would let the client send score updates directly to the leaderboard service. That option is not secure: it is subject to man-in-the-middle attacks where a player can proxy requests and alter scores at will. Therefore scores must be set server-side. The game server (or game logic service) is the only component that should call POST /v1/scores after validating that the user actually won. For server-authoritative games (e.g. online poker), the server may not even need an explicit client request—it knows when a game ends and can update the leaderboard without client intervention.
5. When to Use a Message Queue
Should the game service call the leaderboard service directly, or put events on a message queue?
- Direct call: Simple, low latency. Fits when only the leaderboard (and maybe one other service) needs the event.
- Message queue (e.g. Kafka): When the same score event is used by multiple consumers—leaderboard, analytics, push notifications, anti-fraud—putting the event in a topic lets each consumer process it independently. The game publishes once; the leaderboard service and others consume at their own pace. That also isolates the game from downstream slowness and supports replay or new consumers later. For the rest of this post we’ll assume we use Kafka so we can persist to PostgreSQL and update Redis in parallel without blocking the game.
6. Why a Relational Database Alone Fails
A relational database is ideal for ACID and reporting. For real-time top-K under high write load, it hits a hard limit: getting the top 10 by total score requires aggregating over all score rows.
Persisting each game result: the user_score table.
We need to store every game result for durability, audit, and recovery—so we have a user_score table: one row per game (e.g. user_id, score, created_at). When a user wins we INSERT a new row:
INSERT INTO user_score (user_id, score, created_at) VALUES ('mary1934', 1, NOW());
To get the top 10 we must aggregate and sort:
SELECT user_id, SUM(score) AS total
FROM user_score
GROUP BY user_id
ORDER BY total DESC
LIMIT 10;
To get a user’s rank we need to count how many users have total score greater than or equal to theirs (e.g. a subquery or window over the same aggregation). So both top-10 and rank depend on summing scores per user over the whole table.
The bottleneck: That implies a full table scan and aggregate. With tens or hundreds of millions of rows in user_score, the query rarely finishes in a few hundred milliseconds. Imagine 500 million rows and a refresh every 500 ms, leaving about 450 ms for the query—no relational database can reliably meet that for this pattern.
Upgrade: a materialized leaderboard table.
We could add a second table leaderboard (e.g. user_id, score) with one row per user: on each win we INSERT into user_score (for durability) and UPDATE leaderboard SET score = score + 1 WHERE user_id = ? (or upsert). Then top 10 becomes a simple indexed query:
SELECT user_id, score FROM leaderboard ORDER BY score DESC LIMIT 10;
With an index on score, this can be much faster than aggregating from user_score. The problem is that the leaderboard table still hits hard limits at scale:
-
Rank query. To answer “what is this user’s rank?” we need to count how many users have score ≥ theirs, e.g.
SELECT COUNT(*) + 1 FROM leaderboard WHERE score > (SELECT score FROM leaderboard WHERE user_id = ?). That query still has to scan or traverse a large part of the index (everyone above that score), so with millions of rows it stays expensive and does not scale like O(log N). -
Sync and contention. We have two tables that must stay consistent:
user_score(source of truth for each game) andleaderboard(materialized view for ranking). Every win forces either a double write (INSERT + UPDATE) or a later batch that recomputes fromuser_score. Double write means more load and risk of skew if one write fails. Worse, the same rows inleaderboardget updated over and over—for example the row of the current top player is updated every time they score. Under high QPS many transactions compete to update that row, so the database serializes them (locks) and we get hot spots and latency spikes. The leaderboard table is write-heavy on a small set of rows, which is exactly where RDBMS often struggles. -
Size and query cost. With millions of users, the table and its index are large. Top 10 with
ORDER BY score DESC LIMIT 10can use the index but may still touch many pages; rank queries that count “how many above me” need to walk the index. So we still depend on the database’s sort and scan behavior at large scale, not on a fixed logarithmic cost like in an in-memory sorted structure.
So even with a materialized leaderboard, the RDBMS alone does not give us cheap, real-time rank and top-K at scale. We need a structure that keeps data ordered by score as we write and answers both in logarithmic time—that leads us to Redis Sorted Sets.
7. Redis Sorted Set: Order Maintained at Write Time
Redis provides a Sorted Set (ZSET): unique members (e.g. user IDs) with an associated score, always ordered by score. You can think of it as a Set (unique members) plus a Hash (member → score), with the set sorted. Redis implements it with a skip list and a hash table:
- Hash table: O(1) lookup by member (e.g. “what is user X’s score?”).
- Skip list: O(log N) for insert, update, and rank-based range queries.
Why a skip list is fast: A skip list is built from multiple levels of sorted linked lists. The bottom level—the base list—holds all elements in order (e.g. 1 → 4 → 8 → 10 → 15 → 26 → 36 → 45 → 60 → 68). On top of it, Level 1 keeps a subset of “promoted” nodes (e.g. 1, 8, 15, 36, 60) connected in sorted order; each Level 1 node has a pointer down to the same value in the base list. Level 2 promotes fewer nodes again (e.g. 1, 15, 60) and points down to Level 1. So higher levels act as “express lanes”: you skip over many elements in one step.
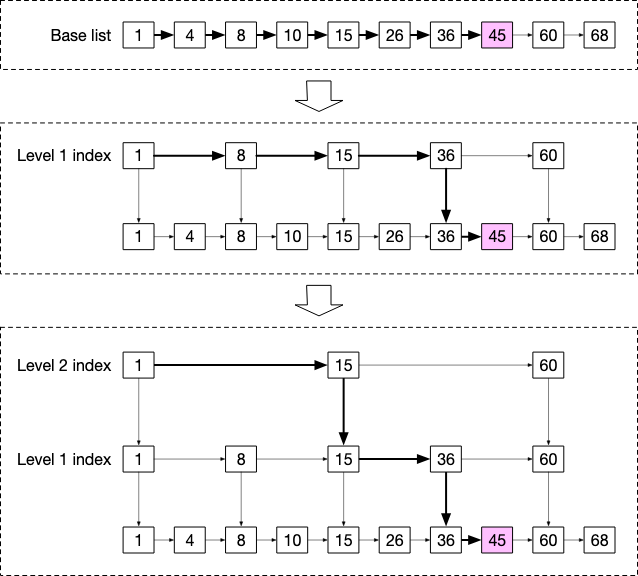
To find a value (e.g. 45), you start at the top level and move right until the next node would be greater than 45—then you drop down one level and repeat. In the figure: start at 1 in Level 2, move to 15, then see 60 > 45 and descend to Level 1 at 15; move to 36, see 60 > 45 and descend to the base list at 36; then step to 45. So instead of walking the whole base list, you do a small number of hops that grows like log N. For 1 million users that’s on the order of ~20 steps instead of millions. That is why ZINCRBY (increment a user’s score) and ZRANGE … REV (get top K) are both O(log N) or O(log N + K)—no full scan.
Redis commands for the leaderboard
Redis Sorted Sets expose a few commands that map directly to what we need. N = number of members in the set, M = number of elements returned.
| Command | What it does | Time |
|---|---|---|
| ZADD key score member | Add a member with a score (or update if it exists) | O(log N) |
| ZINCRBY key increment member | Add increment to the member’s score (insert with that score if new) |
O(log N) |
| ZRANGE key start stop WITHSCORES | Get a range by rank (ascending: lowest rank first) | O(log N + M) |
| ZREVRANGE key start stop WITHSCORES | Same, but descending (highest score = rank 0) — use this for “top K” | O(log N + M) |
| ZRANK / ZREVRANK key member | Get the member’s rank (asc / desc). ZREVRANK = “how many are above me?” + 1 | O(log N) |
We use one Redis key per leaderboard period (e.g. leaderboard_feb_2021). Each month we create a new key and stop writing to the old one; that keeps periods isolated and makes rotation simple.
How we use them in practice
- User scores a point — Increment their score (or add them with score 1 if first time):
ZINCRBY leaderboard_feb_2021 1 'mary1934' - Get top 10 — Ask for the first 10 members in reverse order (highest score first):
ZREVRANGE leaderboard_feb_2021 0 9 WITHSCORES - Get a user’s rank — Ask for their position when sorted high-to-low:
ZREVRANK leaderboard_feb_2021 'mary1934' - Get a window around a user (e.g. 4 above + 4 below) — If their rank is 361, request the range 357–365:
ZREVRANGE leaderboard_feb_2021 357 365 WITHSCORES
Because the set is always kept sorted, we never “sort at query time”—so a single key can serve real-time top-K and rank for one leaderboard at moderate scale.
Rough storage and load
- We store at least user_id (e.g. 24 bytes) and score (e.g. 2 bytes) per user → ~26 bytes per entry.
- Worst case: all 25M MAU have at least one score in the month → 26 × 25M ≈ 650 MB. With skip-list and hash overhead (e.g. 2×), we still fit on one Redis instance.
- At peak (e.g. 2,500 score updates per second), a single Redis node is still within its comfort zone.
8. End-to-End Architecture: A Seven-Step Pipeline
We need three things at once: ingest score events without blocking the game, persist them and keep the ranking store updated, and deliver the top 10 to the UI in real time without overloading the client. The diagram below shows one way to do that in seven steps.
graph TB
subgraph "1. Ingestion"
Game[Game Service]
Kafka1[Kafka topic: game_score]
end
subgraph "2–3. Durability & Ranking"
PGCons[PG Consumer]
RedisCons[Redis Consumer]
PG[(PostgreSQL)]
Redis[(Redis ZSET)]
end
subgraph "4–5. Throttle & Cache"
Kafka2[Kafka topic: leaderboard_change]
CacheCons[Cache Consumer]
Cache[(Cache Top 10)]
Kafka3[leaderboard]
end
subgraph "6–7. UI"
WSCons[WS Consumer]
WS[WebSocket]
REST[REST /leaderboard]
UI[Clients]
end
Game --> Kafka1
Kafka1 --> PGCons
Kafka1 --> RedisCons
PGCons --> PG
RedisCons --> Redis
RedisCons --> Kafka2
Kafka2 --> CacheCons
CacheCons --> Redis
CacheCons --> Cache
CacheCons --> Kafka3
Kafka3 --> WSCons
WSCons --> WS
WS --> UI
REST --> Cache
REST --> UI
Step 1 — Game → Kafka
The game publishes each score event (e.g. user_id, score, created_at) to a game_score topic. Partitioning by user_id keeps events for the same user in order. The game only waits for Kafka to accept the message—not for the database or Redis—so write spikes don’t block players.
Step 2 — Durability: PostgreSQL consumer
One consumer reads from game_score and writes each event into the user_score table. This is the source of truth for analytics, audit, and recovery. You can batch inserts (e.g. flush every 100 records) to reduce DB load; then you must handle failures so no batch is lost.
Step 3 — Ranking: Redis consumer
A second consumer reads the same game_score topic and applies ZINCRBY to the leaderboard key in Redis. After each update it sends a leaderboard_change message to another topic. That message is only a timestamp (or a small signal)—we do not send the full top 10 here. Building the snapshot is the job of the next step.
Step 4 — Throttle (why we don’t push on every score)
We might get thousands of score events per second. If we rebuilt the top 10 and pushed it to the UI on every event, we’d send thousands of updates per second to every connected client—that would overload the browser and the network.
So we throttle: we only rebuild and push the leaderboard at most once every 500 ms (or whatever interval you choose). The leaderboard cache consumer subscribes to leaderboard_change. Each time it receives a message, it checks: “Has at least 500 ms passed since we last refreshed?”
- No → it does nothing (ignores this message).
- Yes → it reads the top 10 from Redis, updates the cache, and publishes the new snapshot (see step 5).
So even with 2,000 score events per second, the UI gets at most about 2 updates per second—still real time to the user, but without the flood.
Step 5 — Cache, enrich, and publish
When the throttle allows a refresh, we read the top 10 from Redis (ZREVRANGE), attach user info (e.g. nicknames). You can either cache all users in Redis for O(1) lookup (fast, more memory) or use cache-aside (look up from DB on miss, then cache; less memory, some extra latency on misses). We store this snapshot in a cache (e.g. a Redis key) and publish it to a leaderboard topic. Optionally we compute a checksum of the top 10 (e.g. from user_id + score) and only publish when the checksum changes, so clients get an update only when the list actually changes.
Step 6 — WebSocket broadcast
A consumer of the leaderboard topic pushes each snapshot to a WebSocket channel (e.g. STOMP /live-updates/leaderboard). Clients that subscribe receive updates as soon as they are published. WebSocket gives a persistent, low-latency connection, so we don’t need to poll over HTTP.
Step 7 — Initial load and reconnection
When a user opens the app or reconnects, they need the current leaderboard right away. A REST endpoint (e.g. GET /leaderboard) returns the cached top 10 from the same cache as step 5. So: first screen from REST, then live updates over WebSocket.
Together, these steps give event-driven ingestion, durability in PostgreSQL, fast ranking in Redis, and real-time delivery to the UI without overloading the client.
9. Database and Data Model (Minimal)
Two tables are enough for persistence and display names:
user_score — one row per game result (source of truth for recovery and analytics):
| Column | Type | Description |
|---|---|---|
| id | BIGSERIAL | PK |
| user_id | BIGINT | User |
| score | INT | Points earned |
| created_at | TIMESTAMP | When |
users — display names (and any other profile fields you need):
| Column | Type | Description |
|---|---|---|
| user_id | BIGINT | PK |
| nickname | VARCHAR | Display name |
PostgreSQL holds the full history; Redis holds the current aggregated score per user (in the ZSET) and the cached top-10 snapshot used by the throttle step and the REST endpoint.
10. Scaling and Extensions
The design so far fits top 10 and moderate RPS. When you need more—higher scale, rank, neighbors, friends—you add the following patterns.
Sharding Redis: fixed vs hash partition
When a single Redis node is not enough (e.g. 500M DAU, much larger data and QPS), we shard. The way we split data determines how easy it is to get top 10 and user rank.
Fixed partition (by score range)
We split the score range into bands (e.g. 1–100, 101–200, …). Each shard owns one band: all users whose score falls in that band live on that shard. On update we need the user’s current score to decide which shard to write to (e.g. from a small cache or DB). When a user’s score crosses into a new band we remove them from the old shard and add to the new.
- Top 10: Only the shard with the highest score band (e.g. 901–1000) can contain the top 10; we query just that shard.
- User rank: We know which shard the user is in. Their global rank = their rank inside that shard plus the total number of users in all shards with higher score bands. We can keep per-shard counts (or size) so we don’t scan. So we get top 10 and rank without talking to every shard.
Hash partition (e.g. Redis Cluster)
The cluster assigns each key to a slot by hash of the key (e.g. CRC16(key) % 16384). So which shard a user lives on depends on their user_id, not their score. As a result, every shard holds a mix of users: some with high scores, some with low. There is no “shard that has the top scores.”
- Top 10: We must ask every shard for its local top K, then merge and take the global top 10 in the app (scatter-gather). Doable, but more work and latency.
- User rank: To answer “what is this user’s rank?” we need to count how many users have score greater than theirs. With hash partition, those users are spread across all shards—because placement is by user_id, not score. So we have to ask every shard: “how many members have score > X?” and add the counts. There is no single ZREVRANK anymore; we do many round-trips and application-side logic. That’s why user rank is awkward with hash partition: no shard knows the global ordering, so rank becomes an expensive scatter-gather over all shards.
For leaderboards where rank and neighbors matter, fixed partition by score range is usually the better fit; hash partition is simpler to operate (e.g. Redis Cluster) but pushes the cost into top-K and especially rank.
Tie-breaking
When two players have the same score, rank by “who reached that score first.” Store user_id → last score timestamp in a Redis Hash. When building the leaderboard or computing rank, compare score first, then timestamp (earlier = better rank). Ties become deterministic and fair.
Recovery
If Redis is lost or corrupted, we rebuild the sorted set from PostgreSQL. The user_score table has one row per game; a script can aggregate per user (or replay in order) and call ZINCRBY for each user to reconstruct the leaderboard. Run it offline or in a maintenance window, then point traffic back to Redis.
Arbitrary rank and “neighbors”
With a single Redis ZSET, ZREVRANK returns a user’s rank and ZREVRANGE returns a slice around them (e.g. 4 above, 4 below)—both O(log N). When we shard by score range, rank works as described above (local rank plus counts from higher bands). “Neighbors” usually live in the same shard or the next band, so we don’t need to query every shard.
Friend leaderboard
“Top 10 among my friends” means we only rank a user’s friends by score. If we updated a dedicated leaderboard per user on every score change (fan-out on write), one score event would trigger an update for each of that user’s friends—e.g. 500 friends ⇒ 500 writes per event, which doesn’t scale. Fan-out on read avoids that: when a user opens their friend leaderboard, we fetch their friend IDs, then fetch those friends’ scores from Redis (e.g. pipelined ZSCORE or a small ZSET), sort in the app, and return. For very large friend lists, precompute and cache periodically.
Durability at scale
When PostgreSQL is not enough (write volume or storage scale), add a wide-column or NoSQL store (e.g. Cassandra, DynamoDB with write sharding) beside or instead of it. That store is the durable source of truth for score events; Redis remains the serving layer for rank and top-K. If Redis is lost, we rehydrate it from the durable store (replay or aggregate by user, then ZINCRBY into Redis). Top K and rank are still read from Redis—scatter-gather and rank across shards are covered in the sharding section above. Separately, when the system is so large that exact rank is too expensive (e.g. many shards), we can show percentile rank instead (e.g. “top 10%”) from precomputed score bands; that’s a product trade-off at hyperscale, not part of the durability design.
11. Conclusion
Designing a real-time leaderboard is about balancing three forces: throughput (thousands of score updates/second), ranking (top-K and rank in O(log N)), and live UX (instant updates without flooding clients).
The core insight: Traditional databases break at scale. Full table scans (GROUP BY over millions of rows) are too slow; materialized views create lock contention on hot rows. Both fail under high write load with sub-500ms requirements.
The solution stack:
- Redis Sorted Sets — O(log N) operations via skip lists; data stays sorted as you write
- PostgreSQL — durable source of truth for audit and recovery
- Kafka — decouple producers from consumers; one write, multiple readers
- Throttle + checksum — collapse thousands of events into ~2 UI updates/second
- WebSocket + REST — initial load via REST, live updates via WebSocket
At scale, sharding strategy matters. Fixed partition by score range makes top-K cheap (query highest band only) and rank tractable (local rank + higher band counts). Hash partition is simpler to operate but forces expensive scatter-gather for both top-K and rank.
Extensions like tie-breaking (timestamp), recovery (rebuild from PostgreSQL), neighbors (ZREVRANGE), and friend leaderboards (fan-out on read) build naturally on this foundation.