With the growth of the travel and technology industries, online hotel booking has become an integral part of the modern travel experience. In this blog post, we’ll explore how to design a scalable hotel booking system that ensures data integrity and handles hundreds of thousands of transactions per day.
At the surface, a hotel booking appears to be a standard e-commerce transaction. However, from a systems architecture perspective, it represents one of the most challenging problems in distributed systems: managing high-contention, finite inventory across a temporal dimension. Unlike a retail item, a hotel room is not a single SKU; it is a perishable asset that represents a different product for every night it remains unoccupied.
Building a Scalable Hotel Booking System: Architecture Deep Dive
Ever wondered what it takes to run a hotel booking platform like Booking.com or Expedia? It might seem straightforward on the surface—users search for rooms, select dates, and make reservations. But behind that smooth experience is a fascinating and complex engineering puzzle that handles hundreds of thousands of bookings daily while ensuring no room is ever double-booked.
Our goal here is to peek behind the curtain and understand the architecture of such a system. We’ll explore how modern booking systems are designed, from managing inventory across time dimensions to handling concurrent booking attempts and coordinating distributed transactions across multiple services.
Every complex booking system must solve three fundamental challenges:
- Accuracy: Maintaining an absolute source of truth for inventory counts across dates and room types
- Concurrency: Orchestrating hundreds of simultaneous attempts to seize the last remaining room without collision
- Resilience: Coordinating state changes across disconnected environments—the database, the cache, and third-party payment gateways
Let’s dive into how we solve these challenges.
1. Understanding the Problem: The Challenge of Booking Systems
The core architectural challenge lies in maintaining strict transactional integrity while operating at a global scale. We must navigate the “double-booking” paradox—ensuring that we never sell the same physical capacity twice—while accounting for dynamic pricing and the inevitable failures of distributed network calls.
To solve these challenges, we need to build a system that maintains accuracy, handles concurrency gracefully, and remains resilient in the face of partial failures. Let’s start by defining what our system needs to accomplish.
2. System Requirements: Defining What We Need to Build
Functional Requirements
Core Requirements:
- Users can search for hotel rooms: The system must support searching rooms based on location, check-in/check-out dates, number of guests, and amenities (pet-friendly, high-speed Wi-Fi, etc.)
- Users can view prices and availability: Display nightly rates and number of available rooms for each room type
- Users can make reservations: Create reservations with payment information and confirm bookings
- Users can cancel reservations: Cancel reservations and process refunds (if policy allows)
- Administrators can manage inventory: Add/edit/delete rooms, adjust prices, and block rooms for maintenance
Out of Scope:
- Integration with specific hotel management systems (PMS)
- Online check-in/check-out services
- Staff and shift management
- Integration with other distribution channels (OTA)
Non-Functional Requirements
- Accuracy: No double-booking allowed beyond the permitted overbooking level (typically 10%)
- Scalability: System must support 5,000 hotels with 1 million rooms, processing approximately 240,000 bookings per day
- Performance:
- Search: 300 QPS for detail pages, 30 QPS for confirmation pages
- Booking: 3-10 TPS average, with ability to handle peak loads many times higher
- Reliability: System must handle partial failures and ensure eventual consistency
- Idempotency: Each booking must be processed exactly once, even with network retries
Back-of-the-Envelope Estimation
System Scale:
- 5,000 hotels with a total of 1 million rooms
- 240,000 bookings per day (assuming 70% occupancy rate and 3-day average stay)
- 3-10 TPS average, but can spike to hundreds of TPS during peak events (flash sales, festivals)
Traffic Model:
- Search: 300 QPS for hotel detail pages
- Confirmation View: 30 QPS
- Booking: 3 TPS
- Read-to-Write Ratio: 100:10:1 (search : view : book)
3. High-Level Architecture: Microservices and Data Modeling
Microservices Architecture
The system is designed with a microservices architecture to isolate search traffic from transactional load:
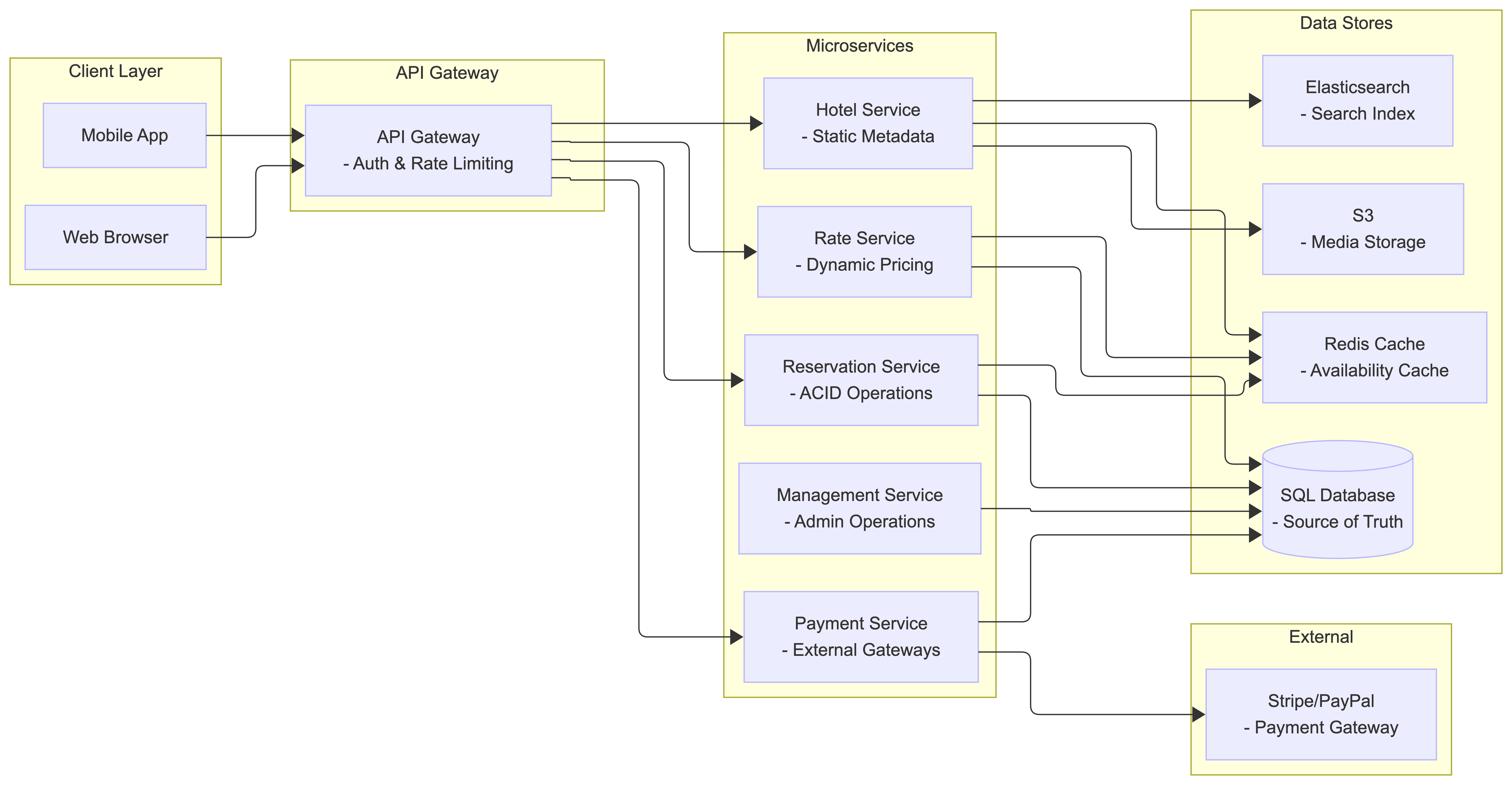
Core Services:
-
Public API Gateway: Manages authentication and rate limiting. Protects internal services from DDoS-level bursts and “noisy neighbor” scenarios.
-
Hotel Service: Serves static metadata (name, address, amenities). High-read volume is offloaded to CDN and edge caches.
-
Rate Service: Determines dynamic pricing. Interaction with the Reservation Service utilizes gRPC with strictly typed Protocol Buffer contracts to prevent calculation drift and ensure deterministic totals.
-
Reservation Service: Manages the inventory lifecycle. Centralizes ACID-compliant operations.
-
Payment Service: Coordinates with external gateways. Isolates the system from external latency and partial failure modes of third-party APIs.
-
Hotel Management Service: Handles administrative inventory adjustments and maintenance blocks.
Data Model: Room Type vs Room ID
A common architectural pitfall is modeling inventory around specific room_id values. In a professional hotel reservation system, guests reserve a room type (e.g., “King Suite” or “Standard Double”) rather than a specific physical room number. Specific room assignments are deferred until check-in. This abstraction simplifies inventory management but introduces a “hot record” problem: because every reservation for a specific type hits the same database row, we maximize the risk of thread contention.
Schema: room_type_inventory
This table supports atomic inventory management over a 2-year rolling window. At our estimated scale (5,000 hotels with ~20 room types each), this table will contain approximately 73 million rows. A scheduled daily job is required to pre-populate this inventory as the window advances.
| Column | Type | Description |
|---|---|---|
hotel_id |
INT | Unique identifier for the hotel (Part of Partition Key) |
room_type_id |
INT | Unique identifier for the room category (Part of Partition Key) |
date |
DATE | The specific night of the stay (Sort Key) |
total_inventory |
INT | Maximum capacity (minus rooms under maintenance) |
total_reserved |
INT | Current count of confirmed allocations |
version |
INT | Incrementing counter for Optimistic Concurrency Control |
110% Overbooking Logic:
Most hotels employ a business rule allowing 10% overbooking to account for statistical “no-shows.” This is implemented as a conditional SQL check:
UPDATE room_type_inventory
SET total_reserved = total_reserved + 1
WHERE (total_reserved + 1) <= (total_inventory * 1.1)
AND hotel_id = ? AND room_type_id = ? AND date = ?;
Separation of Search vs Booking
We recommend a Dual-Store approach:
- Search Operations (Read-heavy): Search operations involving complex geo-filters and amenity metadata should be offloaded to a search-optimized store like Elasticsearch.
- Booking Operations (Write-heavy): The relational database serves strictly as the “Source of Truth” for inventory and booking transactions.
Access Pattern Comparison:
| Feature | Search Access Patterns | Booking Access Patterns |
|---|---|---|
| Traffic Volume | High (Detail: 300 QPS / Confirmation: 30 QPS) | Low (Booking: 3 TPS) |
| Data Requirements | Precomputed availability & amenity filters | High-contention, real-time inventory |
| Consistency Model | Eventual consistency (slight lag is acceptable) | ACID requirements (Strong consistency) |
| Core Technology | Elasticsearch & Redis Aggregates | Relational Database (SQL) |
4. Design Deep Dive: The Booking Journey
4.1. The Search — Finding the Perfect Match
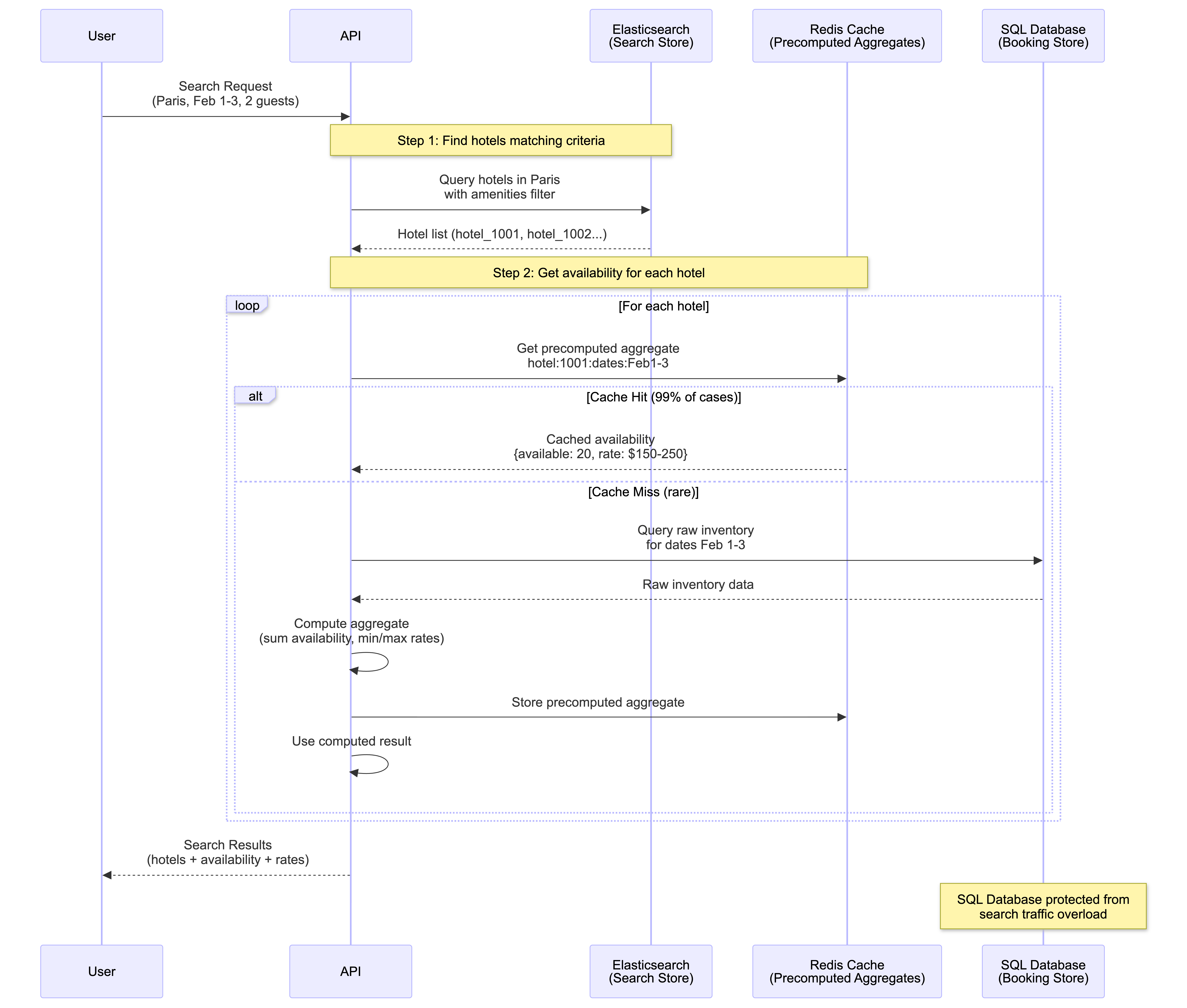
The search phase is the busiest part of the system. Traffic drops quickly at each step: a hotel detail page may receive around 300 queries per second, but only about 30 reach the confirmation page, and roughly 3 turn into actual bookings. Because read traffic is much higher than write traffic (about 100 to 1), we use a dual-store approach to handle this efficiently.
What is the Dual-Store Approach?
The dual-store approach means we use two separate data stores optimized for different purposes:
- Elasticsearch (Search Store): Optimized for read-heavy search operations with complex filters
- SQL Database (Booking Store): Optimized for write-heavy transactional operations with ACID guarantees
This separation prevents heavy search traffic from overwhelming the transactional database that handles actual bookings.
How Search Works with Precomputed Aggregates
When a user searches for hotels, we need two types of data:
- Hotel metadata (name, location, amenities): Stored in Elasticsearch for fast geo-spatial and text-based filtering
- Availability and rates (how many rooms available, price per night): This is where precomputed aggregates come in
Before Precomputation (Raw Data in SQL Database):
The SQL database stores inventory at the most granular level:
-- Raw inventory data in SQL database
room_type_inventory table:
hotel_id | room_type_id | date | total_inventory | total_reserved
---------|--------------|-------------|-----------------|---------------
1001 | 201 | 2026-02-01 | 10 | 3
1001 | 201 | 2026-02-02 | 10 | 5
1001 | 201 | 2026-02-03 | 10 | 2
1001 | 202 | 2026-02-01 | 5 | 1
...
To answer a search query like “Show me hotels in Paris with availability from Feb 1-3”, the system would need to:
- Query Elasticsearch for hotels in Paris
- For each hotel, query SQL database for each date (Feb 1, 2, 3) and each room type
- Calculate availability:
available = total_inventory - total_reserved - Aggregate across dates to show “3 nights available”
This requires multiple database queries per hotel, which is slow and expensive at 300 QPS.
After Precomputation (Aggregated Data in Redis Cache):
Instead, we precompute and cache aggregated results in Redis:
# Precomputed aggregate in Redis
Key: "hotel:1001:room_type:201:dates:2026-02-01:2026-02-03"
Value: {
"available_rooms": 20, # Sum of (total_inventory - total_reserved) across dates
"min_nightly_rate": 150.00, # Precomputed minimum rate
"max_nightly_rate": 250.00, # Precomputed maximum rate
"total_nights": 3,
"last_updated": "2026-01-28T10:30:00Z"
}
Now a search query can:
- Query Elasticsearch for hotels in Paris
- For each hotel, fetch precomputed aggregates from Redis (single fast lookup)
- Return results immediately
Why Precomputed Aggregates Are Perfect for This Use Case:
- Read-Heavy Pattern: Search queries happen 100x more often than bookings (300 QPS vs 3 TPS)
- Acceptable Staleness: A 1-2 second delay in availability is acceptable for search results. Users understand that availability changes in real-time.
- Expensive Computation: Calculating availability across multiple dates and room types requires joins and aggregations that are expensive to compute on-the-fly
- Cache-Friendly: The same search results (e.g., “Paris hotels Feb 1-3”) are requested by many users, making caching highly effective
- Database Protection: By caching aggregates, we protect the SQL database from being overwhelmed by search traffic, ensuring it can handle critical booking transactions
The cache is updated via Change Data Capture (CDC) whenever inventory changes in the SQL database, keeping it reasonably fresh (typically within 1-2 seconds).
4.2. The Reservation State Machine & The “Hold”
When a user moves from searching to booking, the system first creates a temporary hold on the room.
In hotel systems, we separate:
- room_type_id: the type of room (for example, King Suite)
- room_id: the actual physical room number
To keep the system fast and avoid database conflicts, we reserve by room type, not by a specific room. The exact room number is only assigned later, when the guest checks in.
This temporary hold usually lasts 10–15 minutes. It protects the user experience: without it, a user could spend several minutes entering payment details, only to find the room was booked by someone else at the last second.
It also protects hotel revenue. If a user starts booking but never finishes payment, the hold must expire automatically. A time limit (TTL) or background process releases the room so it can be booked by someone else instead of staying locked and unused.
The Reservation Status Lifecycle:
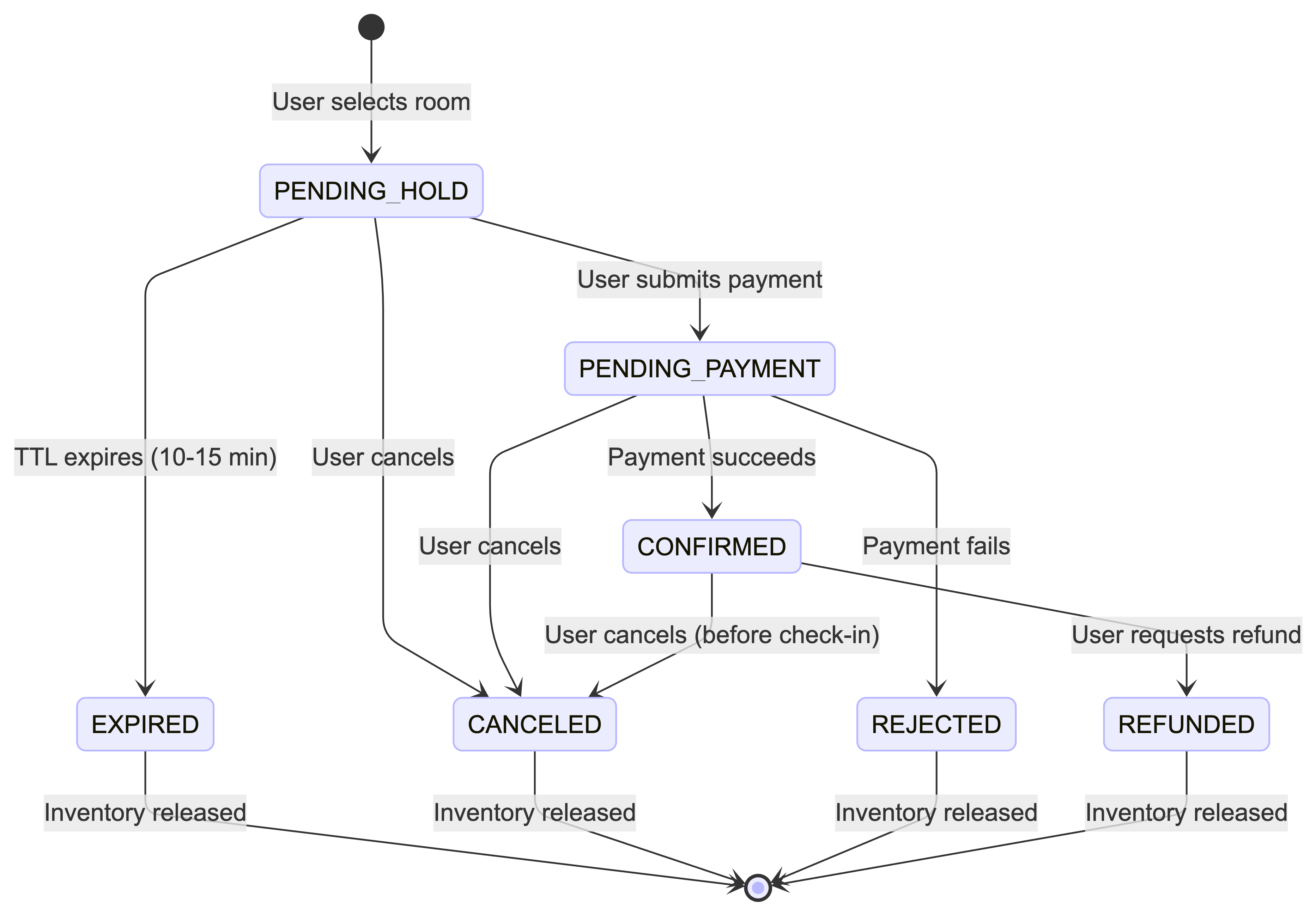
- PENDING_HOLD
The room is temporarily blocked but not yet sold. - PENDING_PAYMENT
The user has submitted payment details, and the system is waiting for the payment result. - CONFIRMED
Payment is successful, and the booking is finalized. - CANCELED
The user cancels the booking, and the room is made available again. - EXPIRED
The hold runs out without payment, and the room is released back to inventory.
4.3. The Backend Battle — Concurrency and Locking
When multiple users attempt to book rooms for the same date range simultaneously, we must prevent double-booking and maintain accurate inventory counts. The core challenge is ensuring total_reserved stays accurate when multiple transactions update the same room_type_inventory row concurrently.
Strategy Comparison Matrix:
| Strategy | How it Works | Pros | Cons |
|---|---|---|---|
| Pessimistic Locking | SELECT ... FOR UPDATE locks the specific row until the transaction commits |
Maximum safety for high-contention rows | Poor scalability; can lead to connection pool exhaustion |
| Optimistic Locking | Uses a version column. Updates only succeed if the version matches the initial read | High performance in low-contention scenarios | High retry rates when many users fight for the same room |
| Database Constraints | A SQL CHECK constraint ensures (total_inventory - total_reserved >= 0) |
Simple, performant, and database-enforced | Less control over specific error messaging to the user |
Recommendation:
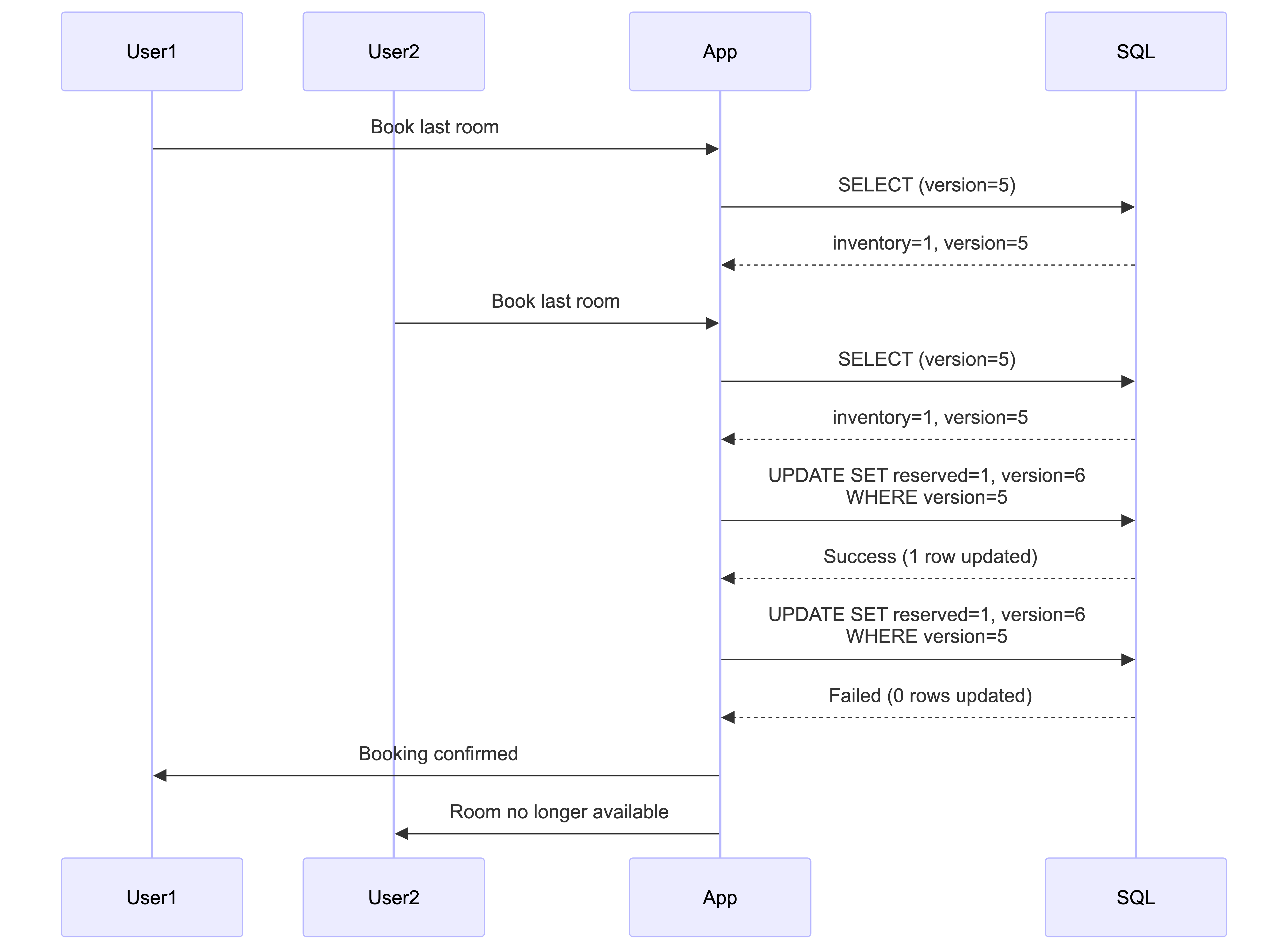
With an average load of ~10 TPS, Optimistic Locking is the pragmatic choice. It uses a version column: updates only succeed if the version matches the initial read. This provides high performance without database-level locks, though retries may occur during spikes.
Data Model: Two Tables Working Together
1. reservations Table - Stores individual bookings:
reservation_id(PK, UUID for idempotency)hotel_id,room_type_id,check_in_date,check_out_datestatus(PENDING_HOLD, CONFIRMED, CANCELED, etc.)total_amount(stored in cents to avoid floating-point errors)
2. room_type_inventory Table - Tracks availability per date:
- Composite PK:
(hotel_id, room_type_id, date) total_inventory,total_reserved,version(for optimistic locking)
Multi-Night Booking Process: Ensuring Atomicity Across Multiple Tables
When a user books multiple nights (e.g., Feb 1-4 = 3 nights), the system must update both the reservations table and multiple rows in the room_type_inventory table atomically. Here’s how optimistic locking works with multiple tables:
The Challenge:
- Insert into
reservationstable - Update multiple rows in
room_type_inventorytable (one per night) - All operations must succeed together, or all must fail
Solution: Database Transaction + Optimistic Locking
We wrap all operations in a database transaction. Optimistic locking still works on each table independently, but the transaction ensures atomicity:
BEGIN TRANSACTION;
-- Step 1: Read current versions for all nights (optimistic locking check)
SELECT date, total_inventory, total_reserved, version
FROM room_type_inventory
WHERE hotel_id = 2001
AND room_type_id = 301
AND date IN ('2026-02-01', '2026-02-02', '2026-02-03');
-- Application logic: Verify all nights have availability
-- If any night unavailable, ROLLBACK immediately
-- Step 2: Create reservation record
INSERT INTO reservations (
reservation_id, user_id, hotel_id, room_type_id,
check_in_date, check_out_date, number_of_rooms,
total_amount, status, expires_at
) VALUES (
'res_abc123', 1001, 2001, 301,
'2026-02-01', '2026-02-04', 1,
45000, 'PENDING_HOLD', '2026-01-28 10:45:00'
);
-- Step 3: Update inventory for each night (with optimistic locking)
-- If ANY update fails (version mismatch), entire transaction rolls back
UPDATE room_type_inventory
SET total_reserved = total_reserved + 1, version = version + 1
WHERE hotel_id = 2001
AND room_type_id = 301
AND date = '2026-02-01'
AND version = ? -- Version from Step 1 read
AND (total_reserved + 1) <= (total_inventory * 1.1);
-- Check: If rows_affected == 0, version changed → ROLLBACK
UPDATE room_type_inventory
SET total_reserved = total_reserved + 1, version = version + 1
WHERE hotel_id = 2001
AND room_type_id = 301
AND date = '2026-02-02'
AND version = ? -- Version from Step 1 read
AND (total_reserved + 1) <= (total_inventory * 1.1);
-- Check: If rows_affected == 0, version changed → ROLLBACK
UPDATE room_type_inventory
SET total_reserved = total_reserved + 1, version = version + 1
WHERE hotel_id = 2001
AND room_type_id = 301
AND date = '2026-02-03'
AND version = ? -- Version from Step 1 read
AND (total_reserved + 1) <= (total_inventory * 1.1);
-- Check: If rows_affected == 0, version changed → ROLLBACK
-- If all updates succeed, commit; otherwise rollback
COMMIT; -- or ROLLBACK;
How It Works:
- Transaction Boundary: All operations wrapped in
BEGIN TRANSACTION…COMMIT/ROLLBACK - Optimistic Locking Per Table: Each
UPDATEchecks theversioncolumn. If version changed since read,rows_affected = 0 - Atomicity Guarantee: If any
UPDATEreturns 0 rows (version mismatch), the application callsROLLBACK, which:- Undoes the
INSERTintoreservationstable - Undoes any successful
UPDATEs toroom_type_inventorytable - Ensures no partial state
- Undoes the
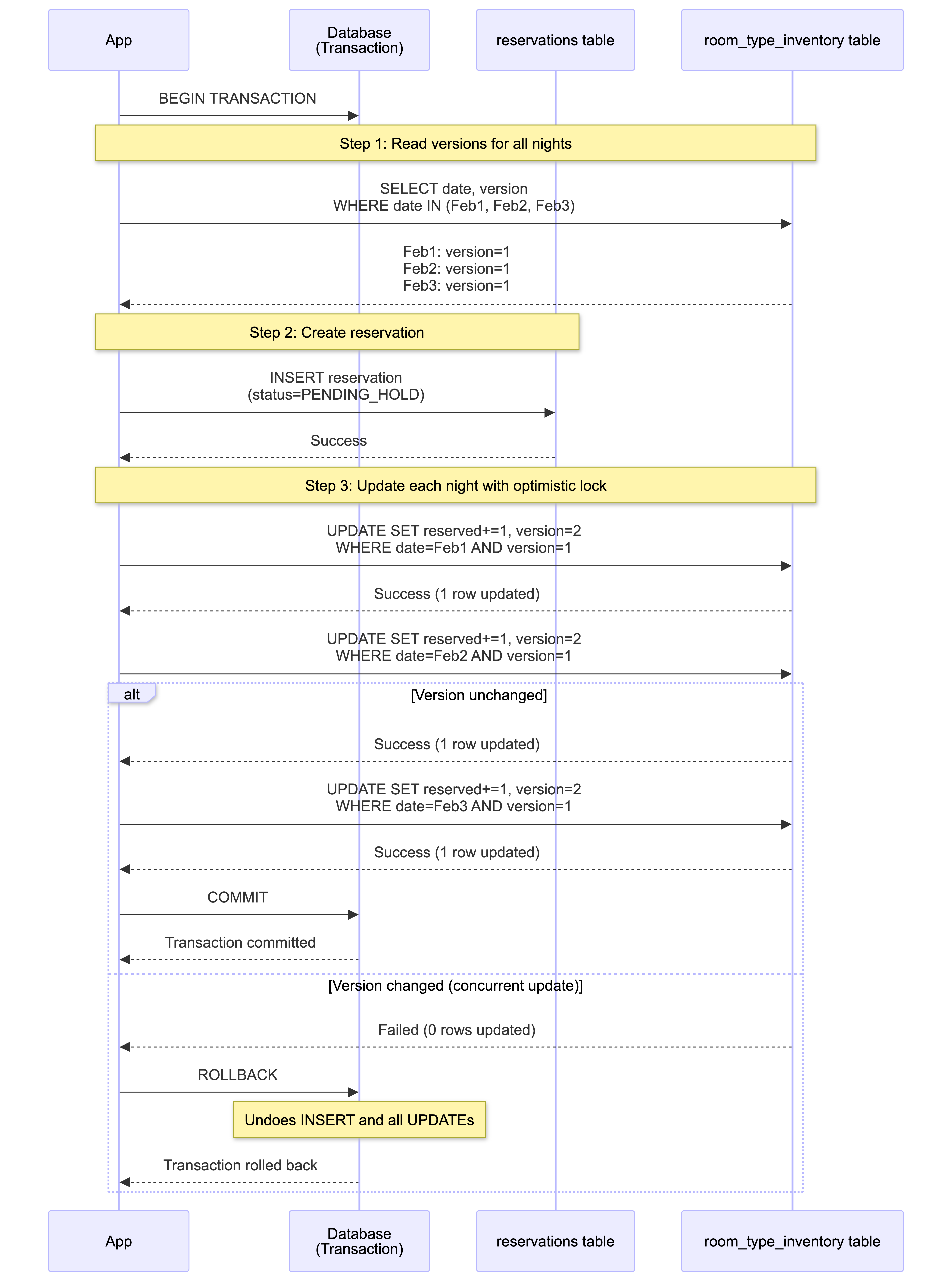
Example: What Happens When Version Changes
Time T1: User A reads versions (Feb 1: version=1, Feb 2: version=1, Feb 3: version=1)
Time T2: User A starts transaction, inserts reservation
Time T3: User B updates Feb 2 (version 1→2) - succeeds
Time T4: User A tries to update Feb 2 with version=1 → FAILS (0 rows affected)
Time T5: User A calls ROLLBACK → Reservation insert undone, no inventory changes
Key Points:
- Transaction ensures atomicity across multiple tables
- Optimistic locking prevents race conditions on each table independently
- Version check happens at UPDATE time, not at transaction start
- Rollback is automatic if any optimistic lock check fails
- Each night is a separate product requiring its own inventory update
- Canceling releases inventory for all nights in the stay
4.4. The Distributed Handshake — Payments and Coordination
Finalizing a booking requires coordinating between our internal database (reservations + inventory) and external payment gateways like Stripe or PayPal. The challenge: we cannot wrap an external API call in a database transaction.
Why Not Two-Phase Commit (2PC)?
Traditional 2PC requires all participants (database and payment gateway) to support the protocol. External payment gateways don’t support 2PC—they’re simple HTTP APIs. Even if they did, 2PC has a blocking problem: if the coordinator fails, all resources remain locked indefinitely.
Solution: Saga Pattern with Zookeeper
We use the Saga Pattern with Zookeeper as a coordination service. A Saga breaks a distributed transaction into a sequence of local transactions, each with a compensating action if something fails.
How Zookeeper Helps:
Zookeeper provides:
- Distributed transaction log: Records the state of each step
- Termination guarantee: If the coordinator fails, another node can pick up the log and drive the transaction to completion
- Compensation orchestration: Coordinates rollback actions when failures occur
The Booking Flow:
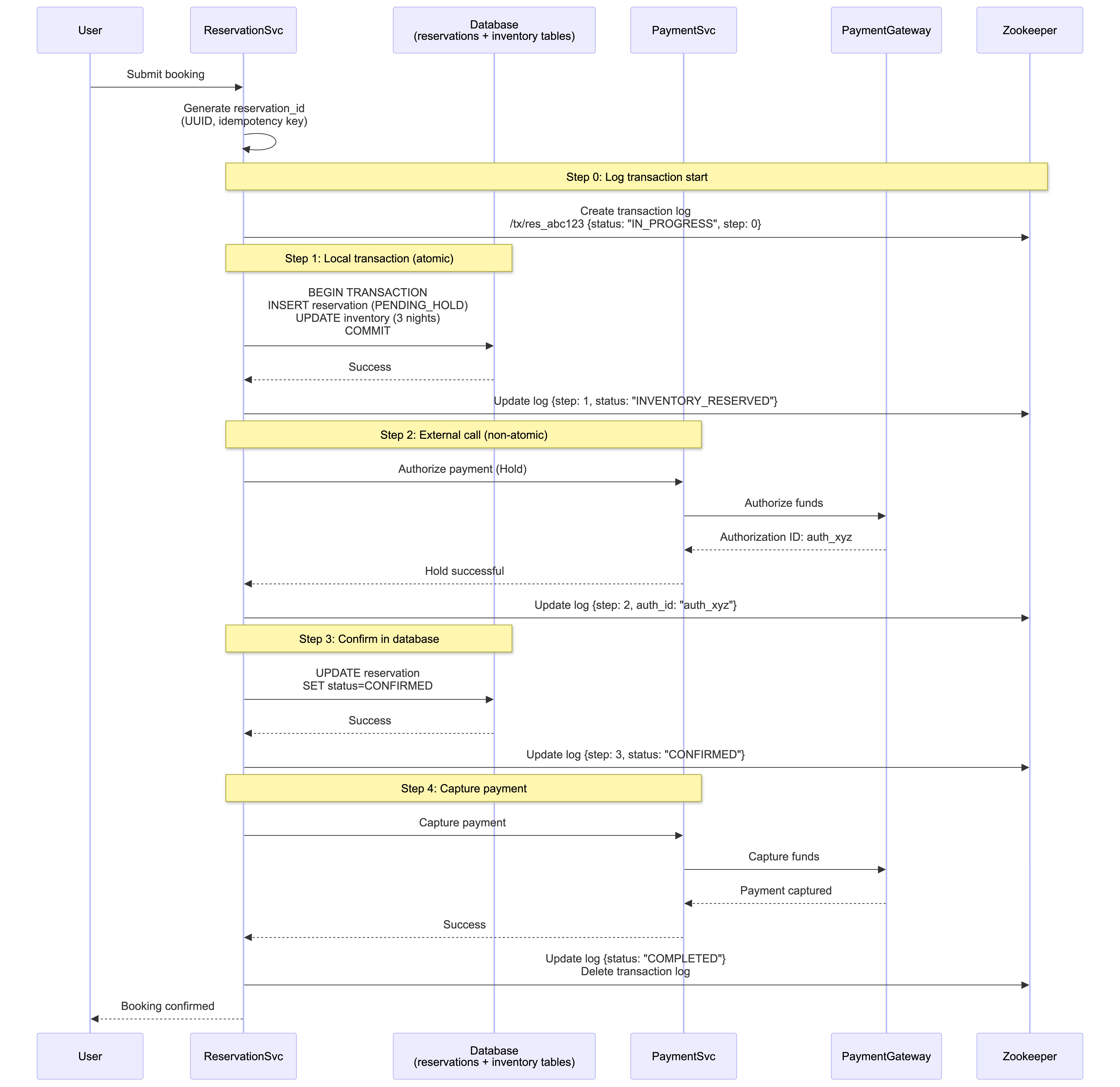
Detailed Steps:
-
Idempotency Key Generation: Generate unique
reservation_idbefore any operations. If retry occurs, database rejects duplicate primary key. - Step 1: Reserve Inventory (Local Transaction):
- Insert reservation record (PENDING_HOLD)
- Update inventory for all nights
- All within one database transaction (atomic)
- Step 2: Authorize Payment (External Call):
- Request payment hold from gateway
- Store authorization ID for later capture
- Not atomic with database—if this fails, we can rollback Step 1
- Step 3: Confirm Reservation:
- Update reservation status to CONFIRMED
- Inventory already reserved, now officially confirmed
- Step 4: Capture Payment:
- Finalize payment transfer
- If this fails, we’ve already confirmed—must use compensation
Handling Partial Failures with Zookeeper:
When a failure occurs, Zookeeper’s transaction log allows recovery:

How Zookeeper Ensures Termination:
- Transaction Log: Each step is logged in Zookeeper with state
- Replication: Zookeeper replicates logs across ensemble (multiple nodes)
- Recovery: If coordinator fails, another node reads the log and continues
- Compensation Scripts: Predefined compensation actions for each step:
- Step 1 failed: Nothing to compensate (no side effects yet)
- Step 2 failed: Release inventory (rollback Step 1)
- Step 3 failed: Release inventory + release payment hold
- Step 4 failed: Refund payment + release inventory
Key Points:
- Reservations and inventory are in the same database - can use local transactions
- Payment gateway is external - requires Saga pattern for coordination
- Zookeeper provides termination guarantee - ensures transaction completes even if coordinator fails
- Compensation actions reverse completed steps when failures occur
- Idempotency keys prevent duplicate operations on retries
4.5. Phase V: Scaling the Journey — Sharding and Global Reach
Scaling a system from a single chain to a global platform requires a “Scalability Playbook” focused on data distribution and cache synchronization:
Database Sharding:
We shard our database by hotel_id. This ensures all transactions for a specific property happen on a single node, maintaining ACID properties. However, we must mitigate Hot Partitions (e.g., a massive resort during a peak holiday). We handle this by adding random suffixes or salting keys to distribute the load if a specific hotel_id exceeds a shard’s QPS capacity.
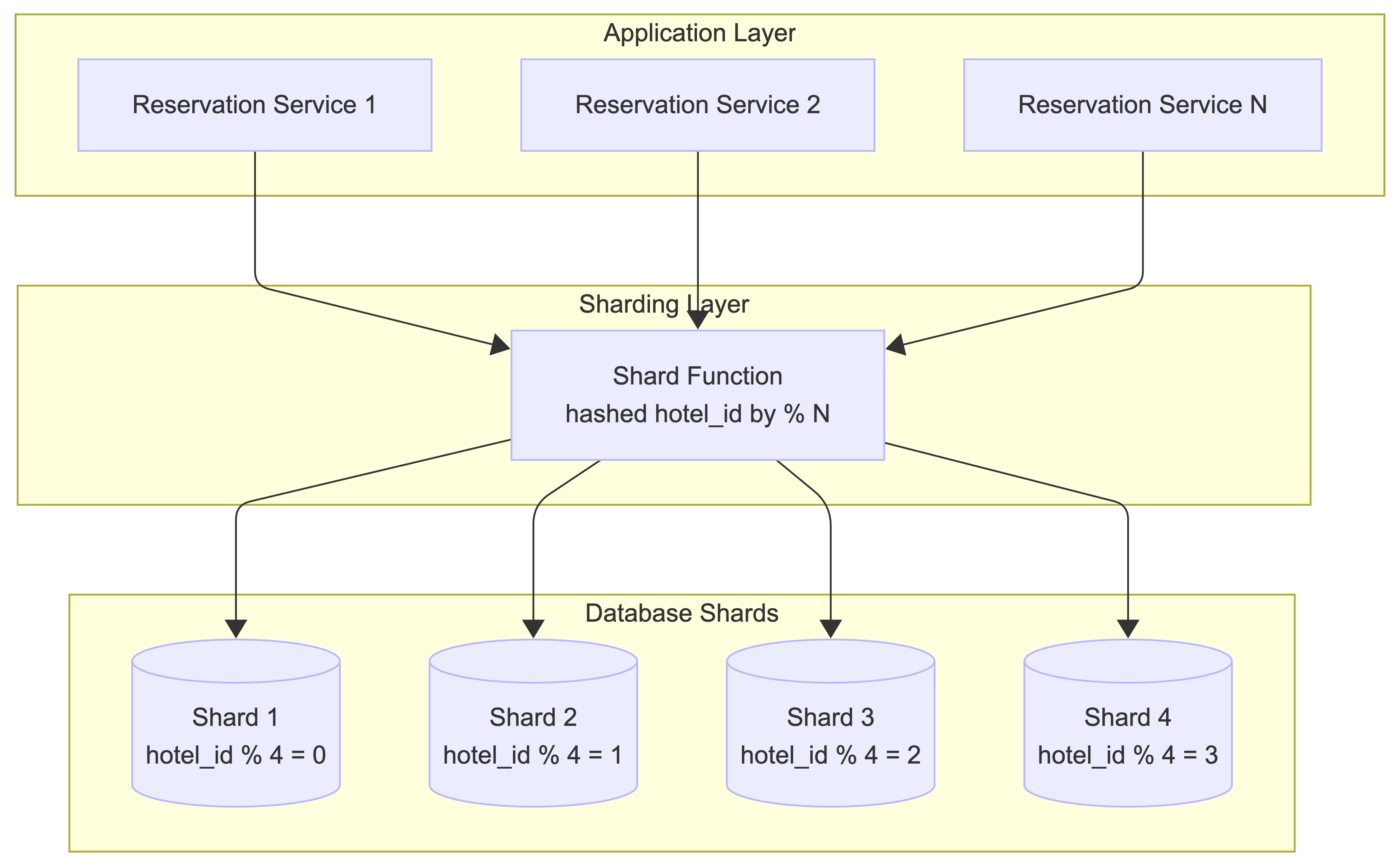
Caching Strategy via CDC:
To keep our high-speed Redis search cache in sync with the Inventory DB (the Source of Truth), we use Change Data Capture (CDC). A tool like Debezium monitors the database transaction logs and streams updates to Redis in near real-time. This ensures that even if the cache is momentarily stale, the database remains the ultimate arbiter of truth.

5. Key Takeaways
We designed a production-grade hotel booking system that handles 5,000 hotels, 1M rooms, and 240K daily bookings. Here’s what matters:
Architecture
- Microservices: Search (300 QPS) separate from Booking (3 TPS) with Dual-Store - Elasticsearch for search, SQL for transactions
- State Machine: PENDING_HOLD → PENDING_PAYMENT → CONFIRMED
- Saga Pattern: Coordinates distributed transactions between database and payment gateway
Critical Design Choices
Concurrency & Data Integrity:
- Optimistic Locking: Version column prevents race conditions at ~10 TPS scale
- Atomic Multi-Night Updates: Either all nights reserved or none—no partial bookings
- Idempotency: UUID
reservation_idprevents duplicate bookings on retry
Data Model:
- Room Type Booking: Reserve by type (King Suite), assign physical room at check-in
- Integer Currency: Store amounts in cents to avoid floating-point errors
- Per-Night Inventory: Each night is a separate product with independent availability
Performance & Sync:
- Redis Cache: Precomputed availability/rates filter search traffic before hitting DB
- CDC (Debezium): Streams database changes to Redis in near real-time
- Database = Source of Truth: Cache can be stale; DB is always authoritative
Scalability
- Shard by
hotel_id: Maintains ACID per property while distributing load - Hot Partition Mitigation: Salt keys when individual hotels exceed capacity
- Zookeeper Coordination: Guarantees transaction completion even if coordinator fails
The Result: Real-time search performance with billing-grade accuracy at scale. The system balances strict consistency (bookings) with eventual consistency (search) based on business requirements.
If you’re preparing for system design interviews or building scalable systems, this hotel booking design demonstrates key patterns for handling high-throughput, accuracy-critical workloads. The techniques covered—optimistic locking, database transactions, distributed transactions with Saga pattern, CDC, and multi-night booking atomicity—apply broadly to distributed transactional systems.